Apache HBase™是一个提供分布式,可扩展,大数据存储的Hadoop数据库。
当需要随机,实时的读/写大数据时,Apache HBase™是非常适合的,HBase的目标就是管理巨大的表比如数十亿行X百万列。HBase与其它数据库的一个鲜明的区别是它是基于列模式而不是通常的行模式。
Apache HBase是开源的非关系数据库,按照Google的Bigtable的结构化数据的分布式存储系统建模。Apache HBase利用Hadoop和HDFS提供分布式数据存储。

在Hbased的数据模型里面有两个重要概念:Row key,Column Family。
Row key是类似为关系数据库中的某行的主键,但是因为Hbase不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来自行设计。例如我们要查询某人最新的一些信息,Row key可以有以下三个部分构成
Column family中文又名“列族”,Column family是在系统启动之前预先定义好的,每一个Column Family都可以根据“限定符”有多个Column。举个例子:
假如系统中有一个User表,按照传统行存储数据库的思路,User表中的列是固定的,如果定义了name,age,sex等属性,User的属性就不能再动态增加。但是如果采用列存储数据库,比如Hbase,那我们可以先定义User表,然后定义一个info列族,User的数据可以分为:info:name = zhangsan,info:age=30,info:sex=male等,如果后来你又想增加另外的属性,只需要使用info:newProperty就可以。如果数据本身的属性是不确定的,采用传统的关系数据库就会比较麻烦,而且关系数据库会造成一些为null的单元浪费,而列存储就不会出现这个问题,在Hbase里,如果每一个column 单元没有值,那么是不占用空间的。
安装
HBase 是构建在Hadoop上的,所以需要先安装jdk、hadoop,关于这部分的安装可以参照这篇文章。
1.先从Apache下载镜像列表中选择一个下载站点,我们使用cnnic。用wget命令下载一个HBase的最新二进制文件镜像。
1
sudo wget http://mirrors.cnnic.cn/apache/hbase/stable/hbase-1.2.4.tar.gz
2.解压下载的文件,并进入到解压后的目录。
1
2 tar xzvf hbase-1.2.4.tar.gz
cd hbase-1.2.4
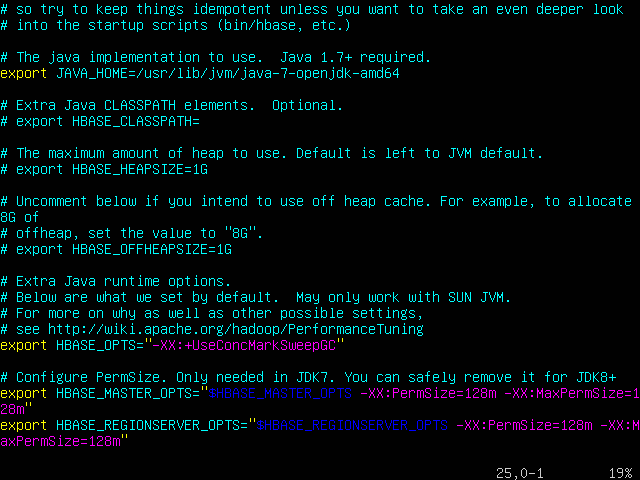
3.设置JAVA_HOME变量。在0.98.5之前的版本,如果未设置变量,HBase会尝试检测Java的位置。对于HBase 0.98.5以上版本,需要在启动HBase之前设置JAVA_HOME环境变量。可以通过操作系统的通常方式设置变量,不过HBase提供了一个配置文件conf/hbase-env.sh,通过这个文件可以设置和HBase相关的一些设置,我们采用这种方式进行设置。编辑此文件,取消注释以JAVA_HOME开头的行,并将其设置为操作系统的相应位置,以Ubuntu 14.04 LTS为例。
4.编辑conf/hbase-site.xml,这是HBase的主配置文件。需要在本地文件系统上指定HBase和ZooKeeper写入数据的目录。默认情况下,在/tmp下创建一个新目录。因为许多服务器配置为在重新引导时删除/tmp的内容,因此应将数据存储在其他位置。以下配置将HBase的数据存储在hbase目录下,名为testuser的用户的主目录中。将1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///home/testuser/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/testuser/zookeeper</value>
</property>
</configuration>
5.提供bin/start-hbase.sh脚本作为启动HBase的快捷方式。发出命令,如果一切正常,则会将一条消息记录到标准输出,以显示HBase已成功启动。
1
bin/start-hbase.sh
您可以使用jps命令验证您是否有一个名为HMaster的正在运行的进程。 在独立模式下,HBase运行此单个JVM中的所有守护程序,即HMaster,它是单个HRegionServer和ZooKeeper的守护程序。
1
jps

OK,如果一切正常,到这里HBase就安装好了。
使用HBase
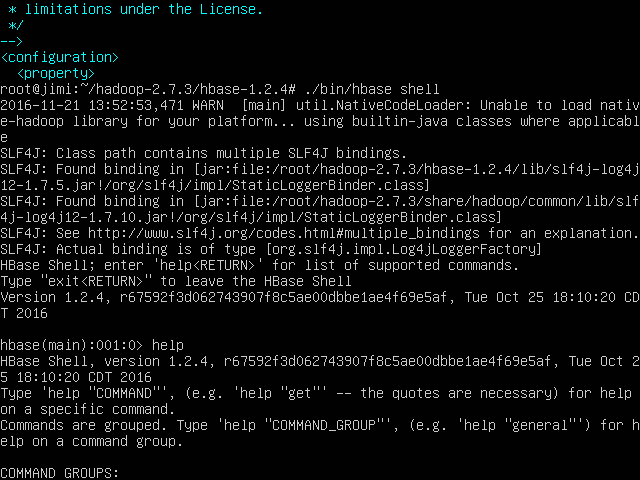
1.连接HBase。
使用位于HBase安装目录下bin目录中的hbase shell命令连接到正在运行的HBase实例。
1
./bin/hbase shell
2.显示HBase Shell帮助文本。
输入help并按Enter键,显示HBase Shell的一些基本使用信息,以及几个示例命令。请注意,表名,行,列都必须用引号字符括起来。
1 | hbase(main):001:0> help |
3.创建表。
使用create命令创建新表,必须指定表名和ColumnFamily名称。
1
hbase(main):002:0> create 'test', 'cf'
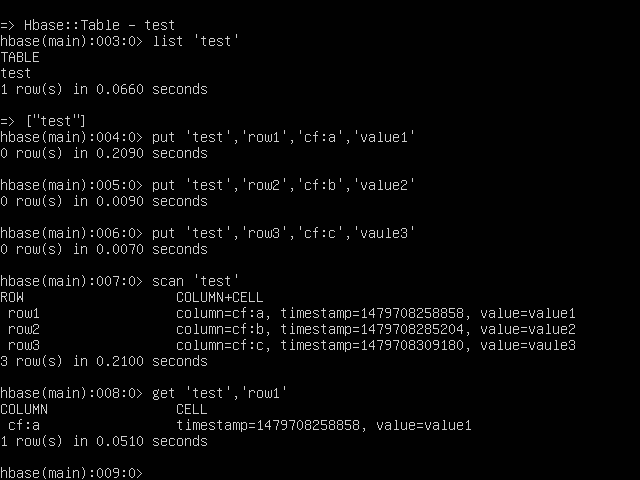
4.列出表的信息,使用list命令:
1
hbase(main):003:0> list 'test'
5.将数据存入表中,使用put命令:
1
2
3hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1'
hbase(main):005:0> put 'test', 'row2', 'cf:b', 'value2'
hbase(main):006:0> put 'test', 'row3', 'cf:c', 'value3'
6.从HBase获取数据的一种方法是扫描。使用scan命令扫描表中的数据。
1
hbase(main):007:0> scan 'test'
7.要一次获取单行数据,可以使用get命令。
1
hbase(main):008:0> get 'test','row1'
8.禁用表。在一些情况下你可能需要删除表、更改其设置等,这时候需要先使用disable命令禁用表。与之对应的可以使用enable命令重新启用它。
1 | hbase(main):009:0> disable 'test' |
9.删除表,使用drop命令。如果不禁用是删除不了的,如下图。
1 | hbase(main):011:0> drop 'test' |
10.退出HBase Shell并断开与集群的连接,使用quit命令。这时候HBase仍然在后台运行。
1
hbase(main):012:0> quit
11.停止HBase
使用bin/stop-hbase.sh脚本停止HBase。
1
./bin/stop-hbase.sh
发出命令后,进程可能需要几分钟才能关闭。使用jps确保HMaster和HRegionServer进程关闭。
附录
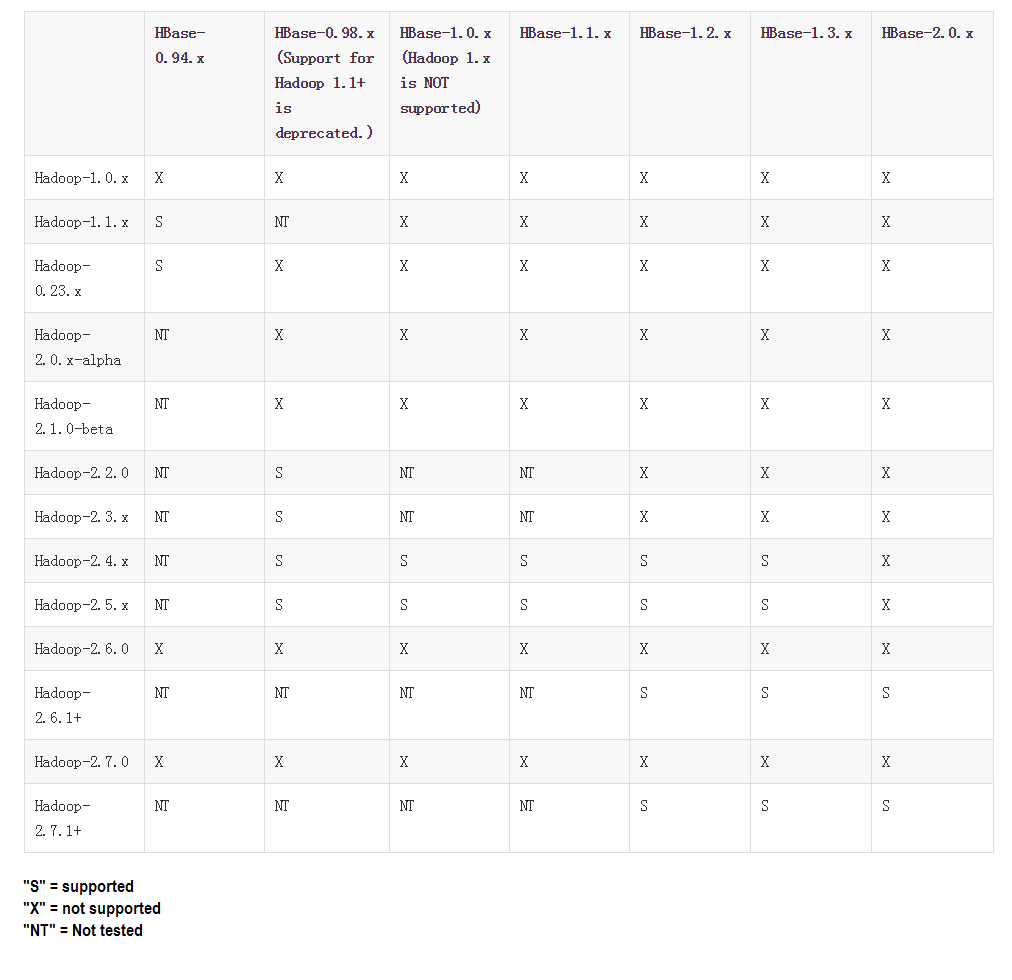
Hadoop和HBase版本对应表: