语音识别系统是深度学习生态中发展最成熟的领域之一。当前这一代的语音识别模型基本都是基于递归 神经网络(Recurrent Neural Network)对声学和语言模型进行建模,以及用于知识构建的计算密集的特征提取流水线。 虽然基于RNN的技术已经在语音识别任务中得到验证,但训练RNN网络所需要的大量数据和计算能力 已经超出了大多数机构的能力范围。最近,Facebook的AI研究中心(FAIR)发表的一个研究论文, 提出了一种新的单纯基于卷积神经网络(Convolutional Neural Network)的语音识别技术,而且 提供了开源的实现wav2letter++,一个完全基于卷积模型的高性能的语音识别工具箱。
在深度学习领域,在语音识别系统中使用CNN并不新鲜,但是大部分应用都局限于特定的任务,而且通常 与RNN结合起来构成完整的系统。但是当前CNN领域的研究表明只使用卷积神经网络也有潜力在语音 识别的所有领域达到最高水平,例如机器翻译、存在长程依赖的语言模型的语音合成等。CNN模型与 其他技术的最大优势在于它不需要额外而且昂贵的特征提取计算就可以天然地对诸如MFCC之类的 标准特征计算进行建模。因此长久以来,深度学习社区一直都期待着在语音识别工作流中完全使用 CNN,因为这要比目前的基于RNN的模型更高效也更富有竞争力。
全卷积语音识别架构
经过很多次实验,FAIR团队决定依赖于一个整合多个不同CNN层的架构来实现端对端的语音识别 流水线,从音频波形处理到语言转录。该架构基于下图所示的散射模型:
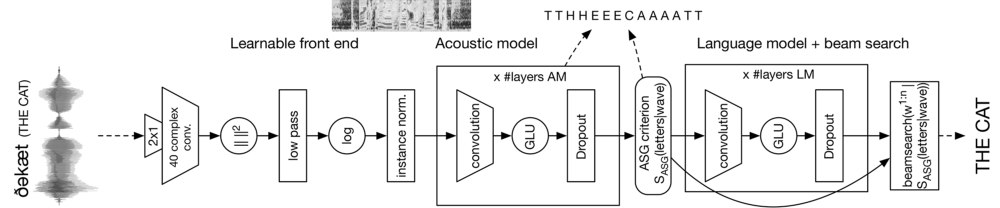
模型的第一层CNN用来处理原始音频并提取一些关键特征;接下来的卷积声学模型是一个具有 门限单元的CNN,可通过训练从音频流中预测字母;卷积语言模型层则根据来自声学模型的 输入生成候选转录文本;最后环节的集束搜索(Beam-Search)编码器则完成最终的转录单词序列。
FAIR团队将其全卷积语音识别模型与最先进的模型进行了对比,它可以用少的多的训练数据 达到基本一致的性能,测试结果令人满意因此FAIR团队决定开源该算法的初始实现。
Wav2letter++
虽然深度学习技术近期的进步促进了自动语音识别(Automatic Speech Recognition)框架和工具 箱的增加。然而,全卷机语音识别模型的进步,激励了FAIR团队创建wav2letter++,一个完全使用 C++实现的深度语音识别工具箱。wav2letter++的核心设计基于以下三个关键原则:
- 实现在包含成千上万小时语音数据集上的高效模型训练
- 简单可扩展模型,可以接入新的网络架构、损失函数以及其他语音识别系统中的核心操作
- 平滑语音识别模型从研究到生产部署的过渡
基于以上原则,wav2letter++实现了如下图所示的非常直白的架构:
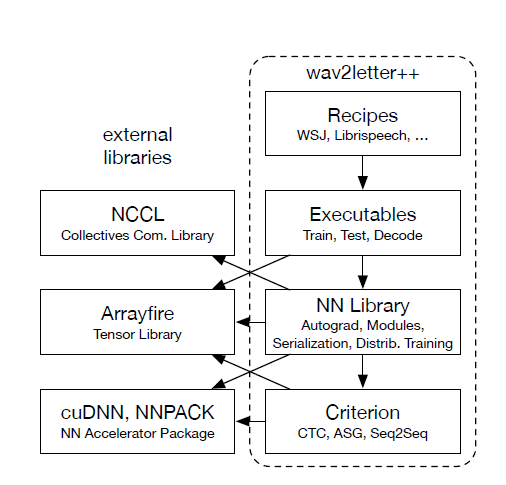
为了更好地理解wav2letter++的架构,有以下几点值得着重指出:
- ArrayFire张量库:wav2letter++使用ArrayFire作为张量操作的基础库。ArrayFire支持硬件无关的 高性能并行建模,可以运行在多种后端上,例如CUDA GPU后端或CPU后端
- 数据预备和特征提取:wav2letter++支持多种音频格式的特征提取。框架可以在每次网络评估 之前即时计算特征,并且通过异步并行计算来实现模型训练的效率最大化
- 模型:wav2letter++包含一组丰富的端对端序列模型,也包含众多网络架构以及激活函数。
- 可扩展的训练:wav2letter++支持三种主要的训练模式:
- train :从零开始训练
- continue :从检查点状态继续训练(continuing with a checkpoint state),
- fork :可用于迁移学习。训练流水线使用并行数据、同步随机梯度下降以及基于NVIDIA的集群通信库,可以无缝伸缩。
- 解码:wav2letter++解码器是基于前面提到的全卷积架构中的集束搜索解码器,它负责输出最终的音频转录文本
Wav2letter++实战
FAIR团队将wav2letter++与其他语音识别进行了对比测试,例如ESPNet、Kaldi和OpenSeq2Seq。 实验基于著名的华尔街日报CSR数据集。初始结果表明wav2letter++在训练周期中的任一方面都 完胜其他方案。
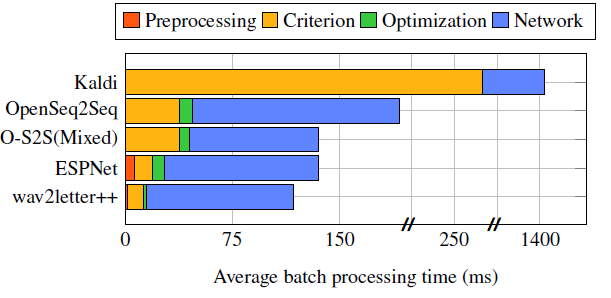
完全基于CNN的语音识别系统当然是一个有意思的实现途径,它可以优化对计算能力和训练数据的 需求。Facebook的wav2letter++实现已经被视为当前最快的语音识别框架之一。我们将在不久的 未来看到该领域越来越多的进步。
汇智网翻译整理,转载请标明出处