Hyperledger Fabric private data是1.2版本引入的新特性,fabric private data是 利用旁支数据库(SideDB)来保存若干个通道成员之间的私有数据,从而在通道之上 又提供了一层更灵活的数据保护机制。本文将介绍如何在链码开发中使用fabric private data。
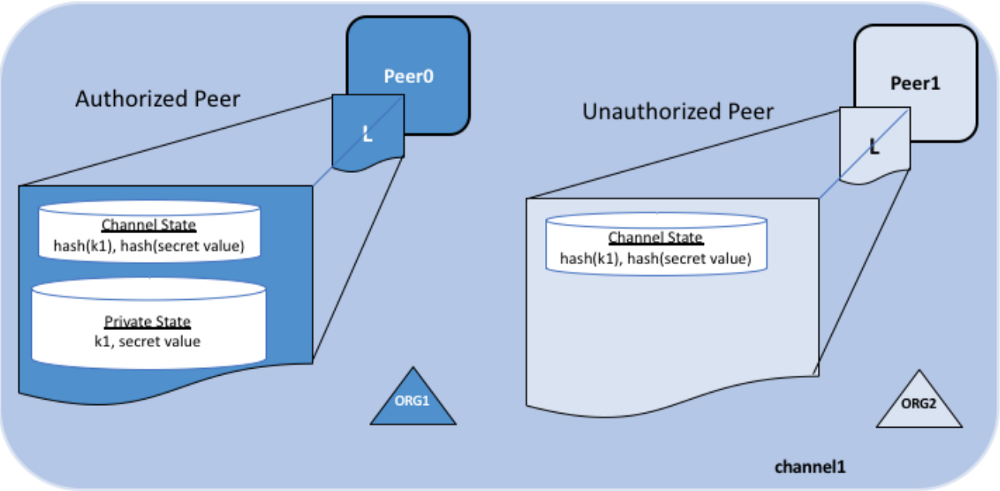
fabric private data用例
我们使用Hyperledger Fabric中经典的fabcar案例来展示如何使用私有数据集。initLedger 函数将在我们的数据集中创建10个新车。所有的这些车辆可以被网络中的任何人查看。现在 让我们创建一个私有数据库,而这个数据将只和我们持有的另一个成员车库共享。
fabric private data数据集配置
我们首先需要一个数据集配置文件collections_config.json,它包含了私有数据集名称和 访问策略。访问策略类似于背书策略,这允许我们使用已经存在的策略逻辑,例如OR、AND等。
1 | [ |
修改链码以支持fabric private data
下面是原始的createCar函数:
1 | async createCar(stubHelper: StubHelper, args: string[]) { |
要把数据加入私有数据集carCollection,我们需要指定目标数据集:
1 | await stubHelper.putState(verifiedArgs.key, car, {privateCollection: 'carCollection'}); |
接下来,要查询车辆的话,我们也需要指定目标私有数据集:
1 | async queryPrivateCar(stubHelper: StubHelper, args: string[]) { |
同样,对于删除和更新操作,都需要指定要操作的目标私有数据集。
fabric private data链码最佳实践
当然,我们的数据中有一部分是Hyperledger Fabric网络中的任何人都看得到的。但是, 其中某些数据是私有的,并且保存在私有数据集中,因此只能被数据集配置文件中定义 的对等节点访问。
我们建议在公开和私有数据集中使用相同的键来保存数据,以便更易于数据的提取操作。
原文:A Beginner’s Guide to SideDBs and Private Data for Hyperledger Fabric Nodejs Chaincode
汇智网翻译整理,转载请标明出处