spaCy是一个流行、易用的Python自然语言处理包。spaCy具有相当高的处理精度, 而且处理速度极快。不过,由于spaCy还是一个相对比较新的NLP开发包,因此它 还没有像NLTK那样被广泛采用,而且目前也没有太多的教程。在本文中,我们将 展示如何使用spaCy来实现文本分类,并在结尾提供完整的实现代码。
1、数据准备
对于年轻的研究者而言,寻找并筛选出合适的学术会议来投稿,是一件相当耗时 耗力的事情。首先下载会议处理数据集, 我们接下来将会议分类论文。
2、浏览数据
先快速看一下数据:
1 | import pandas as pd |
结果如下:

可以用下面的代码确认数据集中没有丢失的值:
1 | df.isnull().sum() |
结果如下:
1 | Title 0 |
现在我们把数据拆分为训练集和测试集:
1 | from sklearn.model_selection import train_test_split |
运行结果如下:
1 | Research title sample: Cooperating with Smartness: Using Heterogeneous Smart Antennas in Ad-Hoc Networks. |
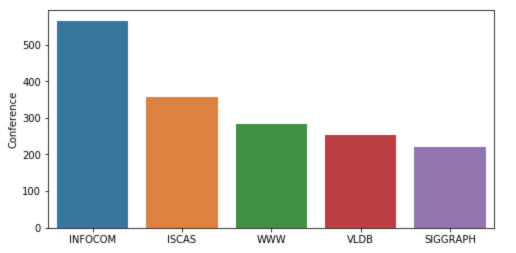
数据集包含了2507个论文标题,已经按会议分为5类。下面的图表概述了论文在不同会议中的分布情况:
下面的代码是使用spaCy进行文本预处理的一种方法,之后我们将尝试找出在前两个类型会议(INFOCOM &ISCAS) 的论文中用的最多的单词:
1 | import spacynlp = spacy.load('en_core_web_sm') |
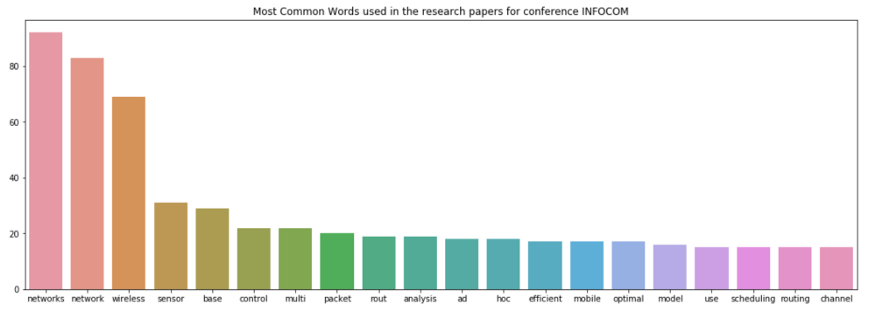
INFORCOM的运行结果如下:
接下来计算ISCAS:
1 | IS_common_words = [word[0] for word in IS_counts.most_common(20)] |
运行结果如下:
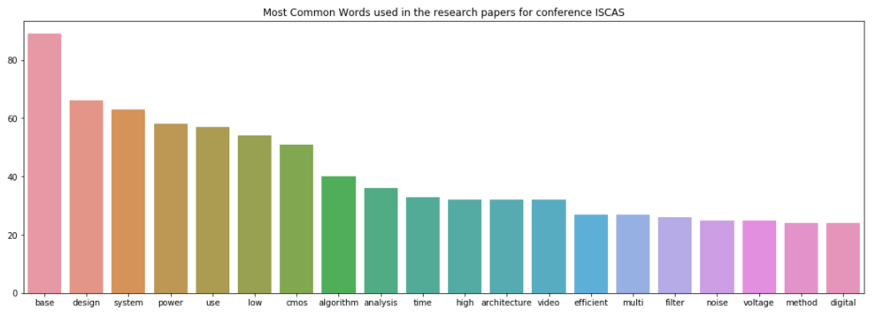
在INFOCOM中的顶级词是“networks”和“network”,显然这是因为INFOCOM是网络领域的会议。 ISCAS的顶级词是“base”和“design”,这揭示出ISCAS是关于数据库、系统设计等课题的会议。
3、用spaCy进行机器学习
首先我们载入spacy模型并创建语言处理对象:
1 | from sklearn.feature_extraction.text import CountVectorizer |
下面是另一种用spaCy清理文本的方法:
1 | STOPLIST = set(stopwords.words('english') + list(ENGLISH_STOP_WORDS)) |
下面我们定义一个函数来显示出最重要的特征,具有最高的相关系数的特征:
1 | def printNMostInformative(vectorizer, clf, N): |
运行结果如下:
1 | accuracy: 0.7463768115942029 |
接下来计算精度、召回、F1分值:
1 | from sklearn import metrics |
运行结果如下;
1 | precision recall f1-score support |
好了,我们已经用spaCy完成了对论文的分类,完整源码下载: GITHUB
原文链接:Machine Learning for Text Classification Using SpaCy in Python
汇智网翻译,转载请标明出处