spaCy是最流行的开源NLP开发包之一,它有极快的处理速度,并且预置了 词性标注、句法依存分析、命名实体识别等多个自然语言处理的必备模型,因此 受到社区的热烈欢迎。中文版预训练模型包括词性标注、依存分析和命名实体识别, 由汇智网提供,下载地址:spaCy2.1中文模型包
1、模型下载安装与使用
下载后将解压到一个目录即可,例如假设解压到目录 /models/zh_spacy,目录结构如下:
1 | /spacy/zh_model |
使用spaCy载入该模型目录即可。例如:
1 | import spacy |
spaCy2.1中文预训练模型下载地址:http://sc.hubwiz.com/codebag/zh-spacy-model/
2、使用词向量
spaCy中文模型采用了中文维基语料预训练的300维词向量,共352217个词条。
例如,查看词向量表大小及维度:
1 | import spacy |
结果如下:
1 | (352217, 300) |
3、使用词性标注
spaCy中文词性标注模型采用Universal Dependency的中文语料库进行训练。
1 | import spacy |
将得到如下的词性标注结果:
1 | 西门子 NNP |
4、使用依存分析
spaCy中文依存分析模型采用Universal Dependency的中文语料库进行训练。
例如,下面的代码输出各词条的文本、依赖关系以及其依赖的词条:
1 | import spacy |
输出结果如下:
1 | 西门子 nsubj 参与 |
也可以使用spaCy内置的可视化工具:
1 | from spacy import displacy |
结果如下:
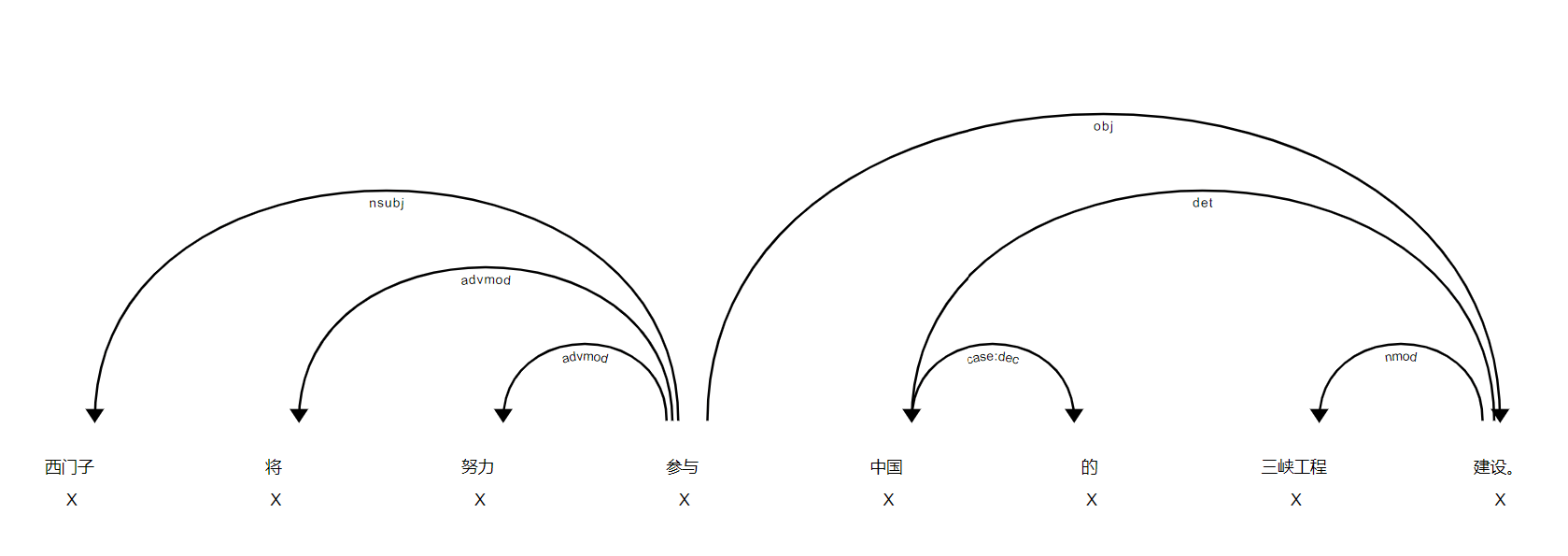
5、使用命名实体识别
spaCy中文NER模型采用ontonotes 5.0数据集训练。
例如:
1 | import spacy |
输出结果如下:
1 | 西门子 ORG |
也可以使用spaCy内置的可视化工具:
1 | from spacy import displacy |
运行结果如下:
