本文是作者一个tweet/微博文本分类实战项目的全程重现与总结。 该项目的最大特点是使用了弱监督技术(Snorkel)来获得海量标注数据, 同时使用预训练语言模型进行迁移学习。
项目的主要步骤如下:
- 采集一小批已标注样本(~600)
- 使用弱监督利用大量未标注样本生成训练集
- 使用一个大型预训练语言模型进行迁移学习
要快速掌握机器学习应用的开发,推荐汇智网的机器学习系列教程。
弱监督
弱监督(Weak Supervision)可以让我们低成本的利用领域专家的知识来程序化的标注上百万级别的 数据样本,从而帮助我们解决人工智能时代的数据瓶颈问题。更确切地 说,这是一个帮助将领域专家的知识编码到AI系统中的框架,专家知识注入的 方式可以采用手写的推理规则或者远程监督。Google在20018年12月刚发了一篇 论文介绍Snorkel DryBell,一个Google自制的内部工具,利用弱监督快速 构建了3个强大的文本分类器。
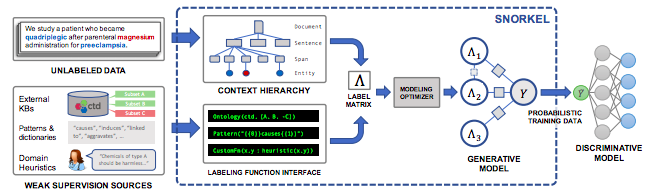
在本文中,我使用和Google一样的工具:Snorkel。斯坦福的Infolab实现的Snorkel 框架叫做Snorkel Metal,建议你 看一下这个教程 以便了解Snorkel的基本工作流程,以及这个教程 来进一步了解它。
在Snorkel中,推理逻辑被成为标注函数(Labeling Function)。有如下这些常见 类型的标注函数:
- 硬编码规则:通常使用正则表达式
- 语义规则:例如,使用spaCy的依存树
- 远程监督:使用外部知识库
- 有噪声人工标注:众包标注
- 外部模型:包含有价值信号的第三方模型
当编写完标注函数后,Snorkel将利用所有标注函数之间的预测结果冲突来训练一个 标注模型。然后,当标注新的数据点时,每个标注函数都会投票:正类、父类或期权。 基于这些投票以及标注函数的权重,标注模型能够地为百万级的数据点自动进行 概率型标注。最终的目标是训练一个可以超过标注函数性能的分类器。
例如,下面是我写的一个用于检测反犹太言论的tweet的标注函数,这个标注函数 主要捕捉与共谋论(犹太富人控制媒体和争执)有关的关键词:
1 | # Set voting values. |
弱监督的主要优点在于:
- 灵活:需要更新模型时,只需要更新标注函数、重新生成训练集和分类器即可
- 提高召回率:判别模型将提供优于弱监督模型的泛化能力,因此可以提高召回率
迁移学习和ULMFiT
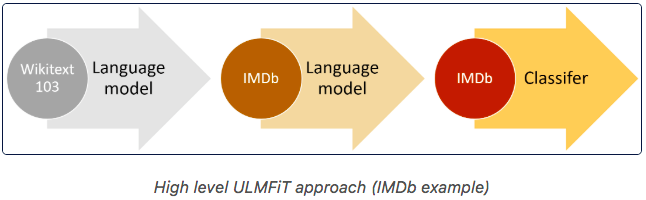
迁移学习(Transfer Learning)对计算机视觉产生了深远的影响。使用一个在ImageNet上 预训练的卷积网络作为初始模型,然后针对你的特定任务进行细调,这种方式已经 非常常见了。但是在NLP领域直到ULMFiT出来后,这一模式才开始为众人所知:
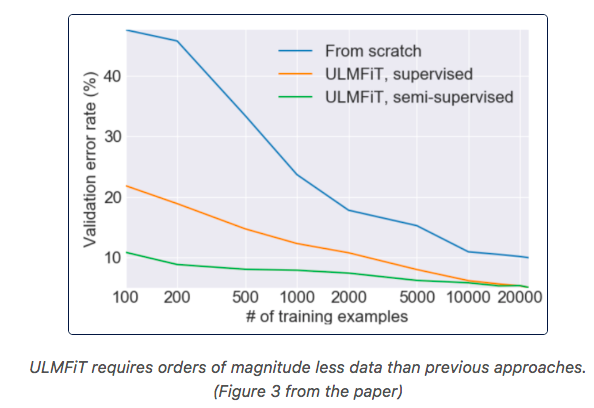
类似于计算机视觉工程师使用ImageNet上预训练的卷积网络,Fastai提供了一个通用 的语言模型,在上百万的维基页面上预训练得到,我们可以对这个模型进行细调来满足 特定问题空间的要求。然后,我们可以训练一个文本分类模型,利用LM上已经学习到的 文本表示,这个训练只需要很少的样本就够了(比从头训练要少1000倍):
UMLFiT的最大优势在于:
- 只需要100个标注,就可以达到使用100倍的数据训练的效果
- Fastai的API非常易用,这个教程非常好
- 得到的Pytorch模型可以在生产环境中部署
接下来我们将深入了一个Tweet分类器的实现过程,我会分享在这一过程中的 收获。
第一步:数据采集和目标设定
采集未标注数据:第一步是采集一大批未标注的数据(至少20000)。对于这个 反犹太tweet分类器,我下载了大约25000条提及单词jew(犹太人)的tweet。
标记600个样本:600不是个大数目,不过对于大多数任务而言我觉得这个数量 都是一个好的起点,因为我们的每个数据集都需要大约200个样本。如果你已经有了 标注好的数据,直接用就可以了。否则,就需要随机选择600个样本进行标注。
你可以使用Google Sheet作为你的标注工具,或者,如果你像我一样喜欢在手机上标注, 那么可以使用免费的Airtable,它有iphone app,而且支持团队协作:
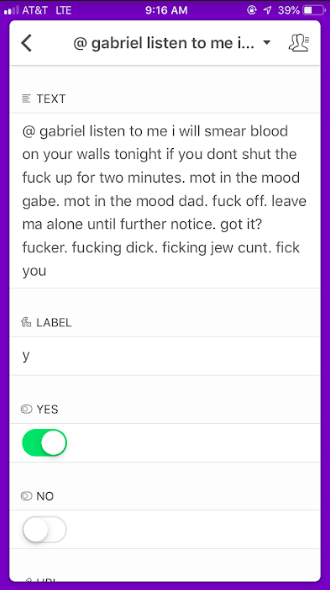
拆分数据集:对于本项目,我们需要一个训练集、一个测试集和一个标注函数数据集。 标注函数数据集的即可以验证标注函数,也可以用于获得编写新的标注函数的思路。测试 集用于检验模型的性能。如果你想做一些超参数调整,你需要一个包含200个样本的验证集。
我有24738个未标注的tweet(训练集),733个已标注的tweet用于构建标注函数,438个 已标注的tweet用于测试。因此我总共标注了1171个tweet,但是我最终意识到可能有点太多了。
1 | DATA_PATH = "../data" |
设定目标:在标注了数百个数据样本之后,你就会对这一工作的艰巨性有更深刻的 认识了,这是可以为自己设定一个目标。我认为,对于反犹太Tweet分类器而言,获得 高精度更重要,因此我设定的目标是至少90%的精度以及30%的召回率。
第二部:使用Snorkel构建训练数据集
编写标注函数是相当工作量的实践阶段,但是这都是值得的!我假设你已经有了相关 的领域知识,那么这一步大约需要一天的工作。
由于绝大多数人之前都没有用到过Snorkel以及弱监督,我将试着尽可能详细地解释这 一方法。这个教程 有助于理解其核心思想,但是跟着我走完下面的流程相信会节省你不少的时间。
下面是标注函数的一个示例,如果tweet中包含了对犹太人的侮辱词,那么就返回 正类/Positive标签, 否则返回 期权 / Abstain:
1 | # Common insults against jews. |
下面是一个返回负类/Negative标签的标注函数,如果tweet的作者提及自己是犹太人,这 通常意味这这个tweet不是反犹太:
1 | # If tweet author is jewish then it's likely not anti-semitic. |
在设计标注函数时,需要记住很重要的一点就是,我们偏重于精确度而非召回率。 我们希望最终分类器去找出尽可能多的模式,提高召回率。但是,如果标注函数 的精度或召回率不够高也没关系,Snorkel有自己的办法。
一旦有了一些标注函数,下面就是构建一个样本和标注函数的矩阵。Snorkel Metal 提供了一个方便函数来显示标注函数的摘要:
1 | # We build a matrix of LF votes for each tweet |
下面是我的24个标注函数的摘要:
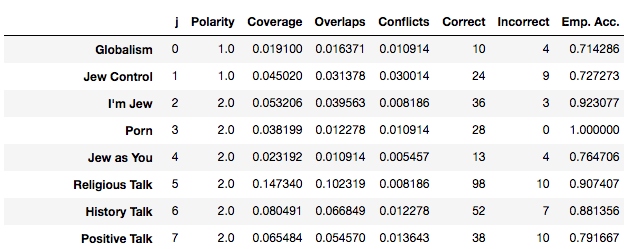
列的含义如下:
- Emp. Accuracy:正确的标注函数预测比例。所有的标注函数都应当不低于0.5。
- Coverage:覆盖率,被成功标注(正或负)的样本占比。需要尽可能提高这个值,同时保持良好的准确率。
- Polarity:标注函数返回值的极性
- Overlaps & Conflicts:一个标注函数与其他标注函数的重叠与冲突情况。标注 模型将使用这些信息来估算每个标注函数的准确率。
让我们检查下覆盖率:
1 | label_coverage(LF_matrix) |
相当不错!
现在,作为基准我们将使用所有标注函数的投票数来预测每个样本的分类。也就是说 如果大多数标注函数的预测为正,那么就将该样本标记为正:
1 | from metal.label_model.baselines import MajorityLabelVotermv = MajorityLabelVoter() |
结果如下:

我们可以看到对于正类我们的F1-score为0.61,为了提高这个指标,我做了一个 表格,在一行内包含tweet、真实分类标签、标注函数分类等各列,目标是找出 标注函数与真实标签不一致的地方,以便修改完善标注函数。
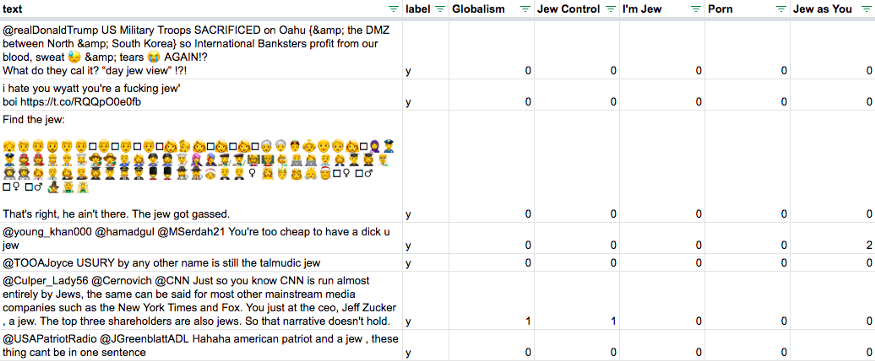
当我把标注函数改善到60%的精度以及60%的召回率时,我就开始训练标注模型了:
1 | Ls_train = make_Ls_matrix(train, LFs) |
现在我们测试标注模型,我使用测试集进行验证,然后绘制P-R曲线。我们可以看到 达到了80%的精度和20%召回,这相当不错。使用标注模型的一个巨大优势就是我们 可以调整预测概率阈值以获得较好的精度。
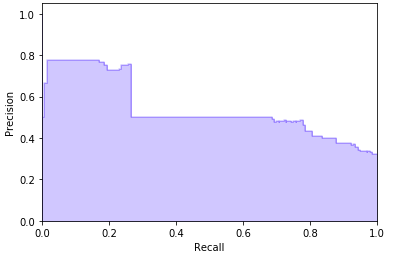
我使用训练集中的头100个最反犹太的tweet对标注模型进行了验证以确信其有效。 现在我们使用标注模型生成训练标签:
1 | # To use all information possible when we fit our classifier, we can |
下面就是我的弱监督工作流:
- 遍历标注集样本,获取新标注函数的思路
- 将新的标注函数加入标注矩阵,准确率不低于50%,并尽可能提高准确率及覆盖率
- 定期使用投票模型更新标注函数集
- 如果投票模型不够好,可以改善标注函数并返回第1步重复
- 一旦投票模型有效,那么就在训练集上跑标注函数,应当至少达到60%的覆盖率
- 接着训练标注模型
- 我在验证标注模型时,使用了我的训练集并打印出100个最反犹太tweet的100个 最不反犹太的tweet来确保其工作正常
现在我们得到了标注模型,可以为25000+个tweet进行概率标注并将其作为训练集了。
现在让我们训练分类模型!
Snorkel的提示:
- 关于LF准确率:在弱监督步骤,我们目标是高精度,所有的标注函数在标注集上 应当至少达到50%的准确率。如果能达到75%甚至更高的话,那就再好不过了
- 关于LF覆盖率:在训练集上应当至少达到65%的覆盖率
- 如果你不是领域专家,那么当你标记初始的600个数据后将得到新的标注函数思路
第三步:训练分类模型
这最后一步用来训练我们的分类器来实现我们手工规则的泛化。
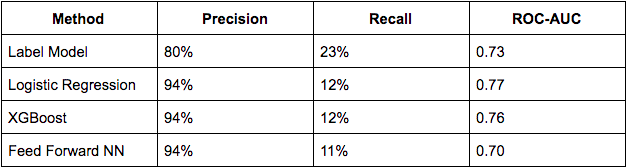
我们将从设定基准开始。我尝试着在不使用深度学习的情况下构建尽可能好 的模型。我尝试了Tf-idf特征、sklearn中的logistic回归、XGBoost和前馈神经网络。
下面是结果,为了得到这些结果我利用开发数据集绘制了Precision-Recall曲线, 然后选择了一个分类阈值,以尽量达到不低于90%的准确度以及尽可能高的召回率。
当我们下载好在wiki上预训练的ULM后,我们需要使用tweet来细调,因为 语言差异相当大。我参照了这个博客 中的代码和步骤,也是用了来自Kaggle的Twitter Sentiment140数据集 微调LM。
我们从该数据集中随机采样了100万条tweet,然后使用这些tweet来微调LM,这样LM 就可以在twitter领域泛化。
下面的代码载入tweet然后训练LM模型:
1 | data_lm = TextLMDataBunch.from_df(train_df=LM_TWEETS, valid_df=df_test, path="") |
我们解冻LM中的所有层:
1 | learn_lm.unfreeze() |
我们让模型运行了20个周期,在每个迭代都保存参数:
1 | for i in range(20): |
现在应当测试一下LM来找点儿感觉:
1 | learn_lm.predict("i hate jews", n_words=10) |
怪异的词条例如xxmaj是fastai添加的帮助文本理解的东西。现在我们 训练分类器:
1 | # Classifier model data |
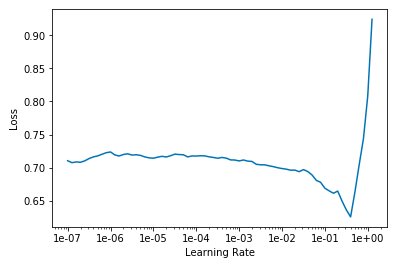
使用fastai的方法来找到一个好的学习率:
1 | learn.lr_find(start_lr=1e-8, end_lr=1e2) |
微调分类器:
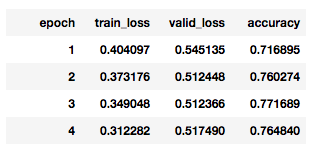
1 | learn.fit_one_cycle(cyc_len=1, max_lr=1e-3, moms=(0.8, 0.7)) |
训练过程:
经过微调,我们绘制P-R曲线!看起来非常不错:
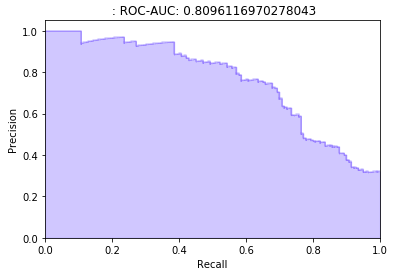
我选的概率阈值为0.63,可以达到95%的准确率和39%的召回率:

模型拾趣
下面是一个相当酷的示例,模型捕捉到了dosen’t的含义:
1 | learn.predict("george soros controls the government") |
这是针对犹太人的侮辱的话:
1 | learn.predict("fuck jews") |
这是一个号召反犹太的tweet:
1 | learn.predict("Wow. The shocking part is you're proud of offending every serious jew, mocking a religion and openly being an anti-semite.") |
这是一些非反犹太的tweet:
1 | learn.predict("my cousin is a russian jew from ukraine- 💜🌻💜 i'm so glad they here") |
弱监督是否真有作用?
我很好奇弱监督这个项目中是否真正起了作用,因此我做了一个小实验。我从整个流程 中拿掉了弱监督环节,然后得到如下的P-R曲线:
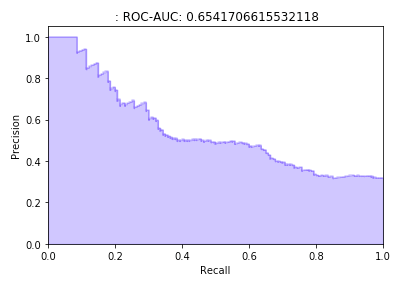
可以看到在召回方面下降很明显。
原文链接:Building NLP Classifiers Cheaply With Transfer Learning and Weak Supervision
汇智网翻译整理,转载请标明出处