要学习目标检测算法吗?任何一个ML学习者都希望能够给图像中的目标物体 圈个漂亮的框框,在这篇文章中我们将学习目标检测中的一个基本概念: 边框回归/Bounding Box Regression。边框回归并不复杂,但是即使像YOLO 这样顶尖的目标检测器也使用了这一技术!
我们将使用Tensorflow的Keras API实现一个边框回归模型。现在开始吧! 如果你可以访问Google Colab的话,可以访问这里。
1、准备数据集
学编程,上汇智网,在线编程环境,一对一助教指导。
我们将使用Kaggle.com上的这个图像定位数据集, 它包含了3类(黄瓜、茄子和蘑菇)共373个已经标注了目标边框的图像文件。我们的 目标是解析图像并进行归一化处理,同时从XML格式的标注文件中解析得到目标物体 包围框的4个顶点的坐标:
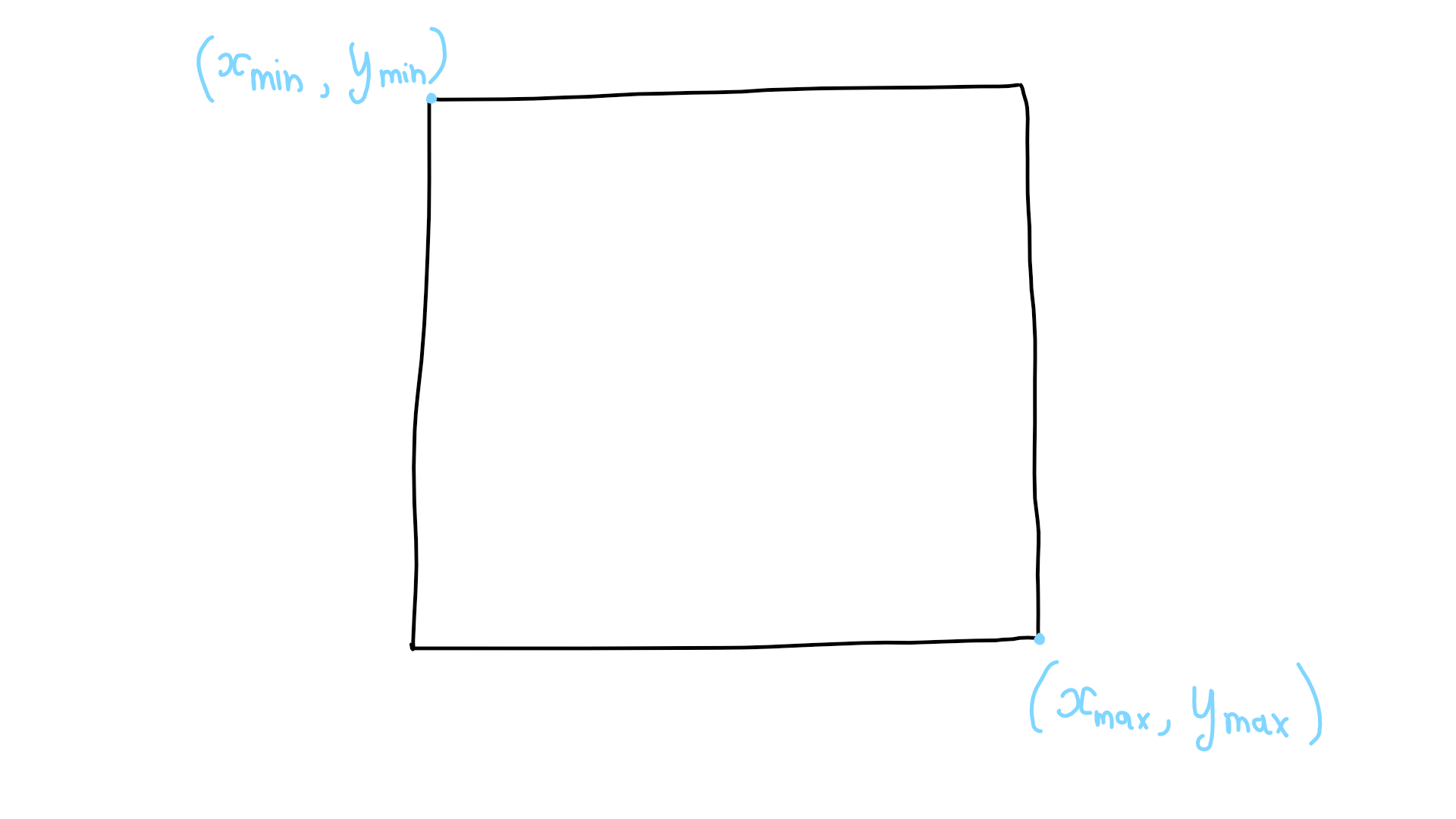
如果你希望创建自己的标注数据集也没有问题!你可以使用LabelImage。 利用LabelImage你可以快速标注目标物体的包围边框,然后保存为PASCAL-VOC格式:

2、数据处理
学编程,上汇智网,在线编程环境,一对一助教指导。
首先我们需要处理一下图像。使用glob包,我们可以列出后缀为jpg的文件,逐个处理:
1 | input_dim = 228 |
接下来我们需要处理XML标注。标注文件的格式为PASCAL-VOC。我们使用xmltodict
包将XML文件转换为Python的字典对象:
1 | import xmltodict |
现在我们准备训练集和测试集:
1 | from sklearn.preprocessing import LabelBinarizer |
3、创建Keras模型
学编程,上汇智网,在线编程环境,一对一助教指导。
我们首先为模型定义一个损失函数和一个衡量指标。损失函数同时使用 了平方差(MSE:Mean Squared Error)和交并比(IoU:Intersection over Union), 指标则用来衡量模型的准确性同时输出IoU得分:
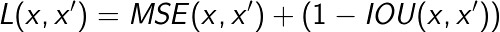
IoU计算两个边框的交集与并集的比率:

Python实现代码如下:
1 |
|
接下来我们创建CNN模型。我们堆叠几个Conv2D层并拉平其输出, 然后送入后边的全连接层。为了避免过拟合,我们在全连接层使用Dropout, 并使用LeakyReLU激活层:
1 | num_classes = 3 |
4、训练模型
现在可以开始训练了:
1 | model.fit( |
5、在图像上绘制边框
现在我们的模型已经训练好了,可以用它来检测一些测试图像 并绘制检测出的对象的边框,然后把结果图像保存下来。
1 | !mkdir -v inference_images |
下面是检测结果图示例:

要决定测试集上的IOU得分,同时计算分类准确率,我们使用如下的代码:
1 | xA = np.maximum( target_boxes[ ... , 0], pred_boxes[ ... , 0] ) |
原文链接:Getting Started With Bounding Box Regression In TensorFlow
汇智网翻译整理,转载请标明出处