Streamlit是第一个专门针对机器学习和数据科学团队的应用 开发框架,它是开发自定义机器学习工具的最快的方法,你可以认为 它的目标是取代Flask在机器学习项目中的地位,可以帮助机器学习 工程师快速开发用户交互工具。
相关链接:Streamlit API中文手册 | Streamlit学习交流群
1、Hello world
Streamlit应用就是Python脚本,没有隐含的状态,你可以使用函数调用
重构。只要你会写Python脚本,你就会开发Streamlit应用。例如,下面
的代码使用streamlit的通用显示方法write
在网页中输出Hello, world!:
1 | import streamlit as st |
结果如下:

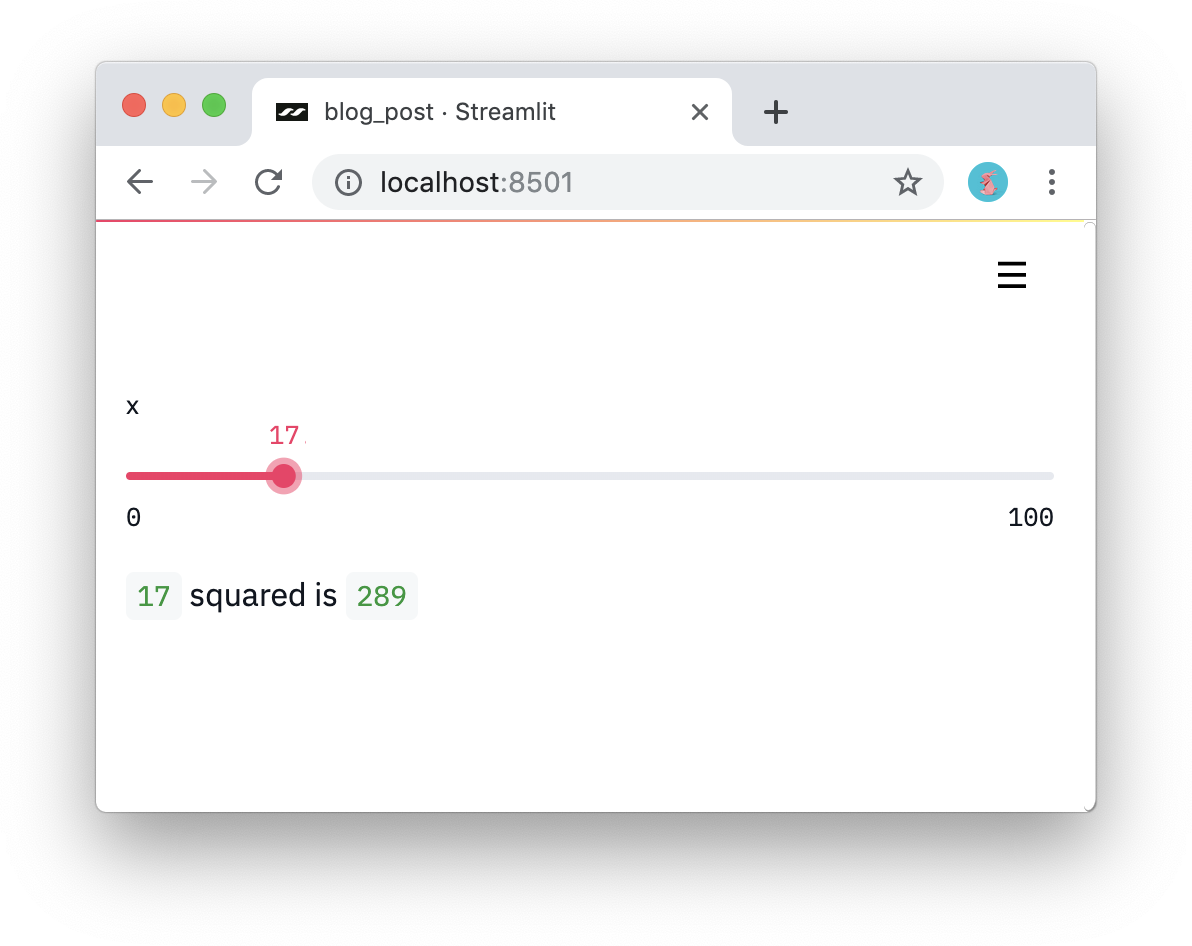
2、使用UI组件
Streamlit将组件视为变量,在Streamlit中没有回调,每一个交互都是 简单地返回,从而确保代码干净。例如下面的代码使用方法slider 创建一个可交互的滑动拉杆,并显示其当前值:
1 | import streamlit as st |
结果如下:
3、数据重用和计算
如果你要下载大量数据或者运行复杂的计算该怎么实现?关键在于 安全地重用数据。Streamlit引入了缓存原语可以让Steamlit应用 安全、轻松的重用信息。例如,下面的代码只需要从Udacity的自动 驾驶车项目下载一次数据,从而得到一个简单、快速的应用:
1 | import streamlit as st |
结果如下:
简而言之,Streamlit的工作方式如下:
- 对于用户的每一次交互,整个脚本从头到尾执行一遍
- Streamlit基于UI组件的状态给变量赋值
- 缓存让Streamlit可以避免重复请求数据或重复计算
或者参考下图:

如果上面的内容还没有说清楚,你可以直接上手尝试Streamlit!
1 | $ pip install --upgrade streamlit |
这会自动打开本地的web浏览器并访问Streamlit应用:
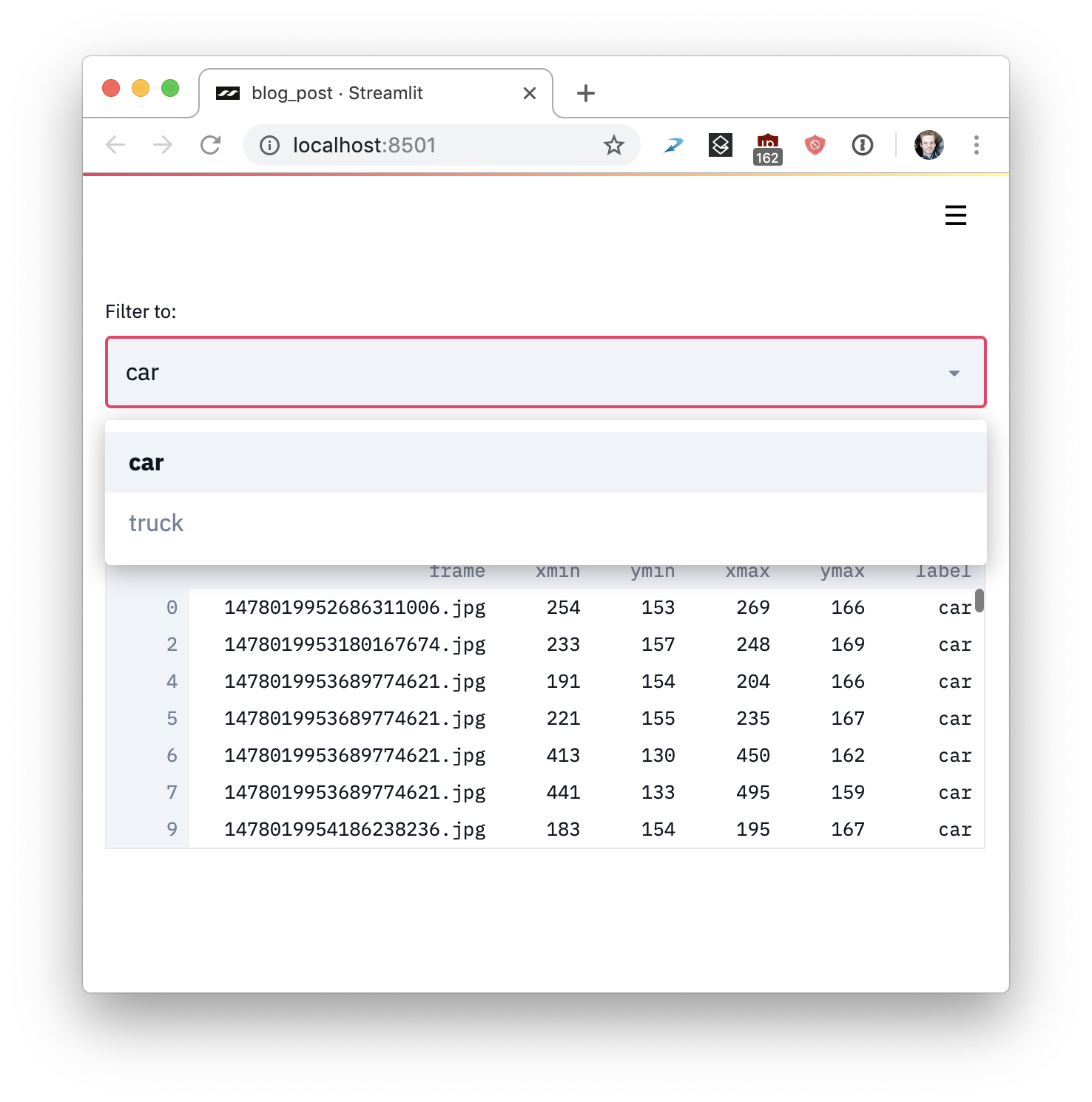
4、实例:自动驾驶数据集工具
下面的Streamlit应用让你可以在整个Udacity自动驾驶车辆照片数据集 中进行语义化搜索,可视化人工标注,并且可以实时运行一个YOLO 目标检测器:

整个应用只有300行Python代码,绝大多数是机器学习代码。实际上 其中只有23个Streamlit调用。你可以尝试自己运行:
1 | $ pip install --upgrade streamlit opencv-python |
原文链接:Turn Python Scripts into Beautiful ML Tools
汇智网翻译整理,转载请标明出处