NLTK是进行自然语言处理的领先的Python开发包。在这个教程中,我们 将使用NLTK开发库创建一个简单的聊天机器人。
聊天机器人是一种人工智能软件,利用它你可以通过网站、手机App或电话 等途径和用户进行自然语言对话。聊天机器人可以在不同的行业中应用于不同 的场景。
1、导入开发包及数据
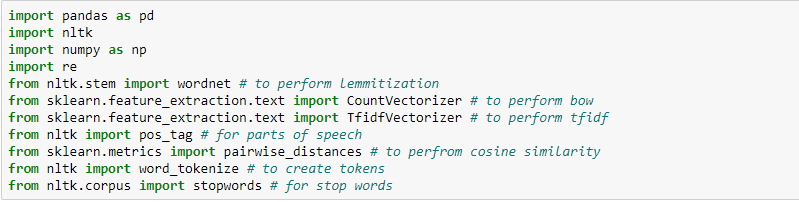
首先导入必要的开发包:
然后将数据集导入Pandas数据帧:
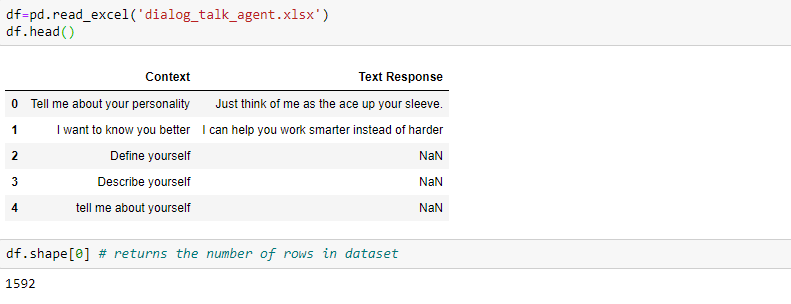
上面的数据包含1592个样本,每个样本为两个字段,分别表示查询及响应文本。
可以看到数据集里有空值,是因为样本数据是分组的,每组的不同查询文本都
对应相同的相应文本。我们可以使用ffill()进行处理:

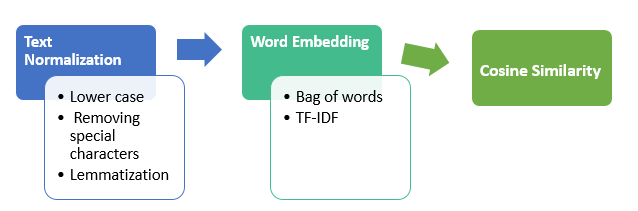
2、处理步骤
首先执行第一步,文本规范化处理。我们将所有的数据转化为小写,删除特殊符号,
提取词干。这部分代码我们使用函数step1进行封装:
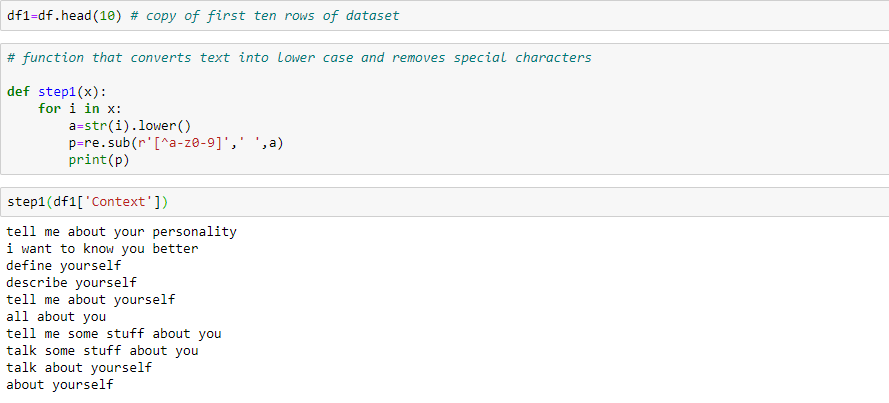
可以看到文本已经干净多了。分词指的是将文本字符串切分为词条:

pos_tag函数返回每个词条在文本中的作用:

我们现在将创建一个函数来整合上面这些环节的代码:
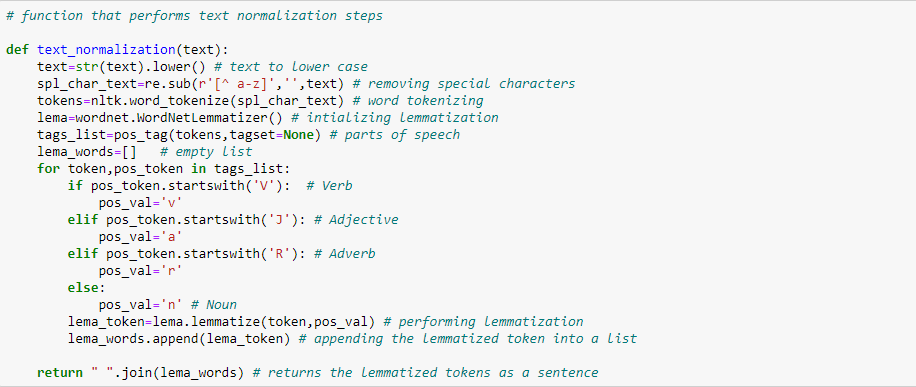
让我们用这个函数处理数据集:

下一步是单词嵌入表示,两次词义相近的词,其嵌入表示的距离也相近。 有两种模型可以用于这个处理环节:词袋模型和tf-idf模型。
3、词袋模型
词袋模型是描述文本中出现的单词的一种表示方法。例如,假设我们的 词典中包含单词{Playing, is, love},我们希望矢量化文本“Playing football is love”, 那么得到的矢量就是: (1, 0, 1, 1)。
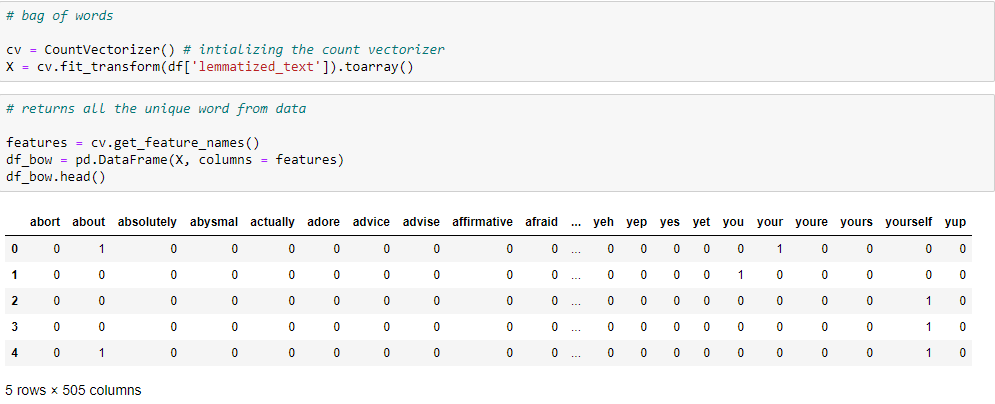
上图表格中的第一行,显示了数据集的第一个样本的BOW模型,只有1和0。
停止词指的是那些经常出现的单词,因此这些单词对于特定的文本来说意义 就不大,我们可以把这些单词从词典中排除出去。下面是预定义的停止词:
考虑下面的示例,我们尝试获取查询对应的响应:
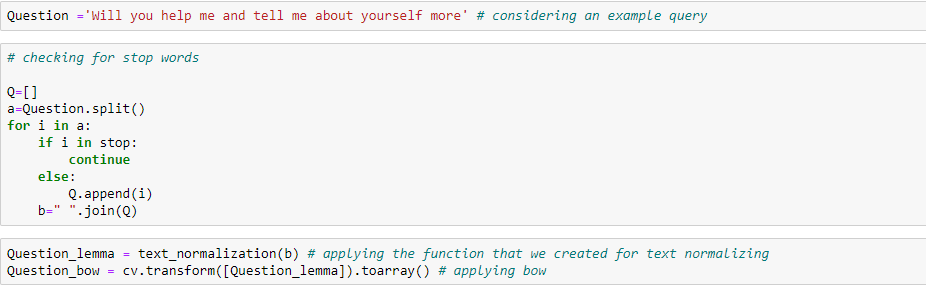
上面的代码中,我们可以看到对于查询‘Will you help me and tell me about yourself more’ , 我们进行文本规范化处理然后转化为词袋表示。下面我们将使用余弦相似算法来 找出相关的相应文本。
4、余弦相似性
余弦相似性是衡量两个矢量相似性的一种指标。其计算方法是用两个矢量的点积除以两个矢量 的模的乘积:
1 | Cosine Similarity (a, b) = Dot product(a, b) / ||a|| * ||b|| |
计算代码如下:
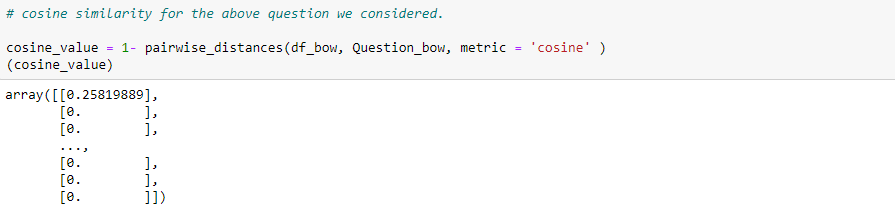
可以看到194#样本的相似性最高,让我们输出其查询文本看看是否相关:

的确是相关的!
5、TF-IDF模型
tf指的是词频,表示单词在当前文档中出现的频率,idf指的是逆文档频率, 表示单词在文档集中出现的频率倒数。这里我们说的文档表示一个样本, 文档集表示所有的样本。
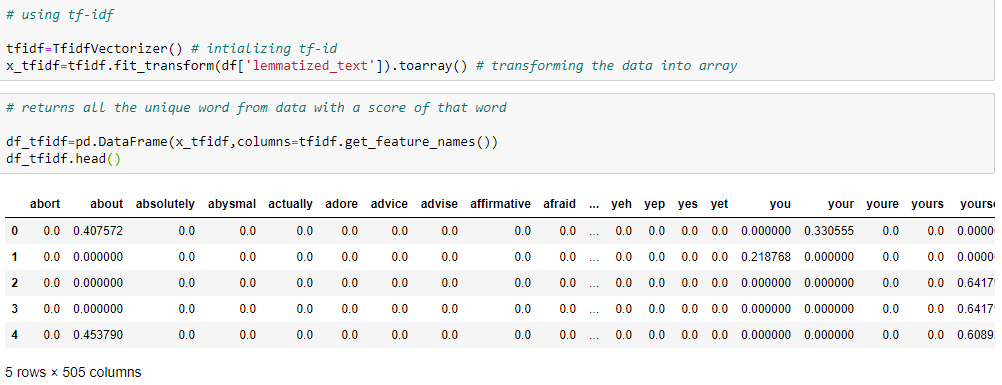
上面是使用tf-idf处理得到的值。现在使用余弦相似算法来找出相关的响应。
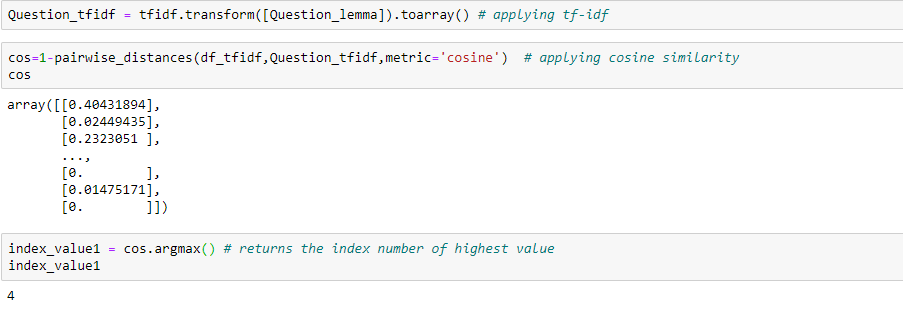
4#样本的相似度最高,让我们显示出来看一下:

使用tf-idf我们得到一个不同的响应,不过看起来也很好!
现在让我们组织一下代码:

看看其他响应:
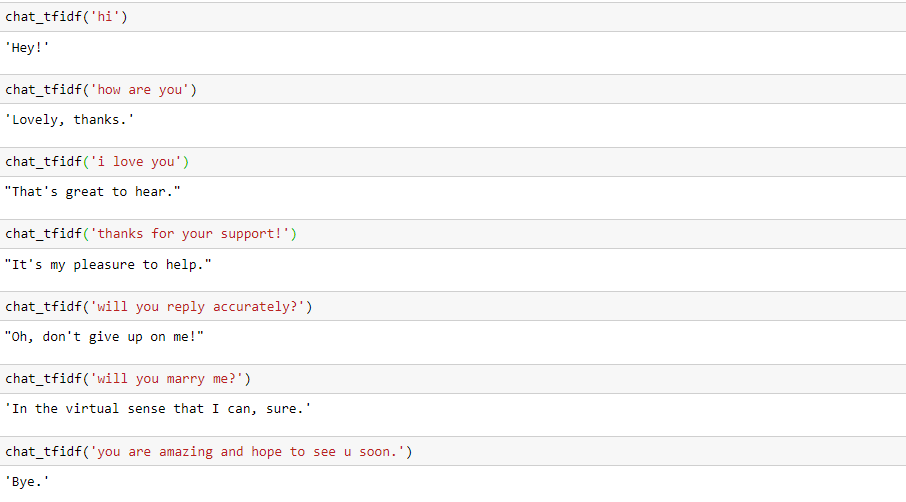
Coooooooooooool!
6、总结
Conclusion:
我们也可以实现词袋版本的对话。我们创建的模型没有使用任何人工智能, 但是效果还是不错的。完整的代码可以在这里获取。
原文链接:A Chatbot in Python using nltk
汇智网翻译整理,转载请标明出处