在这个教程中,我们将实现一个基于电影内容本身相似性的推荐系统。 我们将利用自然语言处理(NLP)技术来提取每个电影的特征,然后 建立不同电影之间的余弦相似性矩阵,最后利用相似矩阵来推荐指定 电影的10个最相似电影。
当我们评价互联网上的产品和服务时,我们表达并分享出来的 倾向性,被推荐系统用来生成个性化推荐。最常见的例子就是 亚马逊的商品推荐、谷歌的搜索结果推荐和Netflix上的视频推荐。
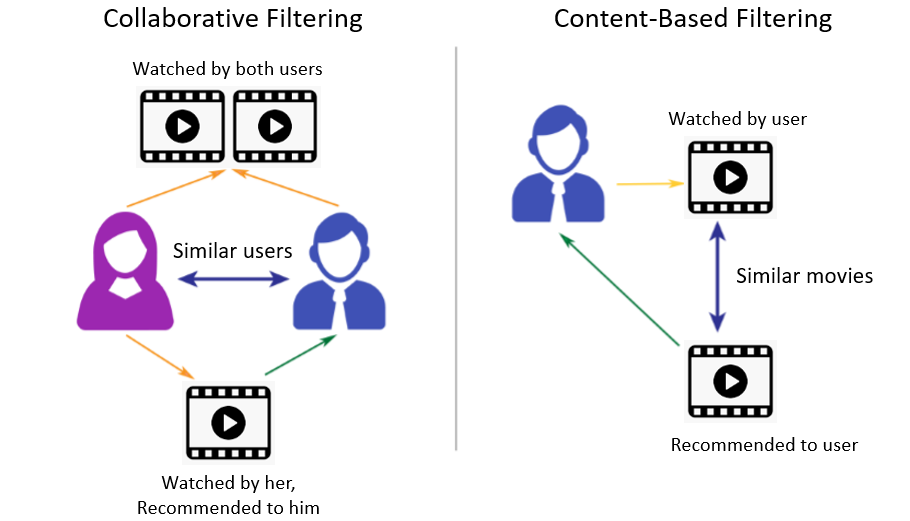
有两种类型的推荐系统:
- 协同过滤 - 基于用户的评价和消费行为来分组相似的用户,然后向用户推荐可能感兴趣的产品或服务
- 基于内容的过滤 - 基于产品/服务本身的相似性向用户推荐
在这个教程中,我们将利用电影的特征,例如风格、剧情、导演和主要演员等,来计算 不同电影之间的余弦相似度。我们使用从data.world下载的IMDB前250部英文电影 作为我们的数据集。
1、导入Python库和数据集
确保已经安装了RAKE库,或者参考以下命令安装:
1 | pip install rake_nltk |
然后使用以下代码读入数据集:
1 | from rake_nltk import Rake |
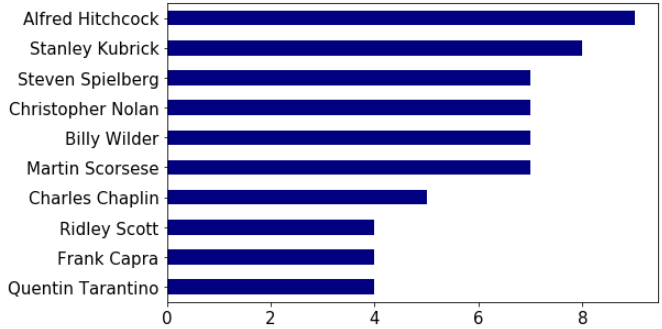
数据集中有250部电影(行),每部电影包含38个属性(列)。不过我们只需要 用到其中的5个属性: ‘Title’, ’Director’, ’Actors’, ’Plot’, and ’Genre’。 下面的代码显示10个流行的导演的作品数量直方图:
1 | df['Director'].value_counts()[0:10].plot('barh', figsize=[8,5], fontsize=15, color='navy').invert_yaxis() |
2、数据预处理
首先使用NLP对数据进行预处理,将属性合并为一列,然后进行矢量化, 每个单词对应一个得分,最后计算余弦相似性得分。
我们使用Rake函数来提取剧情列中整句话的最相关单词,并将提取结果 放入一个新的列‘Key_words’:
1 | df['Key_words'] = '' |

演员和导演的名字被小写并转换为唯一标识值。我们将姓、名合并,这样 Chris Evans和Chris Hemsworth就不会有相似性,否则的话,这两个 名字就会有50%的相似性,因为都包含了Chris:
1 | df['Genre'] = df['Genre'].map(lambda x: x.split(',')) |

3、创建单词的表示
在数据预处理之后,这四个列‘Genre’, ‘Director’, ‘Actors’ 和 ‘Key_words’ 合并为一个新 的列‘Bag_of_words’,这样最终的数据帧只有2列:
1 | df['Bag_of_words'] = '' |

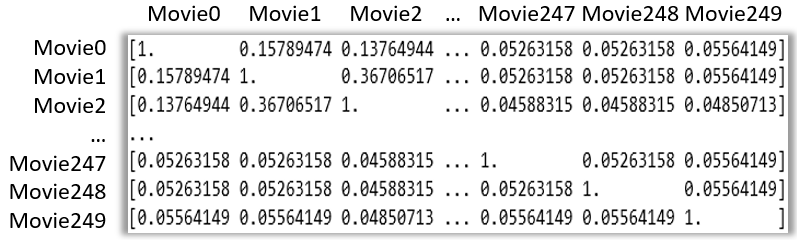
4、创建相似性矩阵
推荐模型只能读取并比较向量,因此我们需要将Bag_of_words列使用CountVectorizer
转换为向量表示,这是一个简单的频率计数器。一旦我们得到了所有单词的计数矩阵,
就可以利用cosine_similarity函数来比较电影的相似性。
1 | count = CountVectorizer() |
接下来是创建电影标题序列,序列的索引对应相似矩阵的行和列。
1 | indices = pd.Series(df['Title']) |
5、运行测试推荐模型
最后一步是创建一个函数,以电影标题为输入,返回其最相似的10个电影。 这个函数将输入电影标题与相似矩阵进行比较,以降序提取相似的电影:
1 | def recommend(title, cosine_sim = cosine_sim): |
现在我们可以测试模型了。输入“The Avengers” 看看推荐结果:
1 | recommend('The Avengers') |

6、源代码
你可以在这里下载源代码。
原文链接:Content-based recommender using Natural Language Processing (NLP)
汇智网翻译整理,转载请标明出处