Raft共识插件是在Hyperledger Fabric 1.4.1后引入的,与之前 已有的Solo共识和Kafka共识相比,Raft共识更适合生产环境。本文 将介绍共识的基本概念、Raft共识的原理并深入探讨基于Raft共识的 Hyperledger Fabric排序服务。
1、共识的基本概念
共识算法可以让机群协同工作,并且可以容忍部分成员主机的故障。 通常我们提到主机的故障会区分两种情况对待:拜占庭故障和非拜占庭故障。
比特币是第一个解决了拜占庭故障的去中心化系统,它的方法是 使用工作量证明共识(POW)。在一个存在拜占庭故障的系统中, 不仅会发生主机崩溃的问题,而且某些成员可能会存在恶意行为 去影响整个系统的决策过程。
如果一个分布式系统可以处理拜占庭故障,那么它就可以容忍任何 类型的错误发生。常见的支持拜占庭故障的共识算法包括PoW、PoS、 PBFT和RBFT。
Raft只能处理非拜占庭故障,也就是说Raft共识可以容忍系统崩溃、 网络中断/延迟/包丢失等故障。常见的支持非拜占庭故障的共识算法 或系统包括:Raft、Kafka、Paxos和Zookeeper。
那么,Hyperledger Fabric为什么不使用可以容忍拜占庭故障的共识 机制呢?那样不是更安全吗?
一个原因在于系统的复杂性与安全性的设计折中。假设一个系统中可能同时 有n个节点发生拜占庭故障,那么拜占庭容错要求系统至少有3n+1个节点 存在。例如,为了应对100个潜在的恶意节点,你至少需要部署301个节点。 这就让系统更复杂。Raft则只需要2n+1个节点来应对潜在的n个节点的 非拜占庭故障,显然复杂性和成本要低一些。因此有些分布式系统还是 更倾向于Raft,尤其是考虑到像Hyperledger Fabric这种许可制的联盟链 环境中,通常会使用数字证书等安全机制来增强安全性,因此存在恶意 节点的可能性很小。
2、Raft共识的基本原理
Raft是一个分布式崩溃故障容错共识算法,它可以保证在系统中部分节点 出现非拜占庭故障的情况下,系统依然可以处理客户端的请求。从技术上来讲, Raft是一个管理复制日志(Replicated Log)的共识算法,复制日志是 复制状态机(RSM:Replicated State Machine)的组成部分。
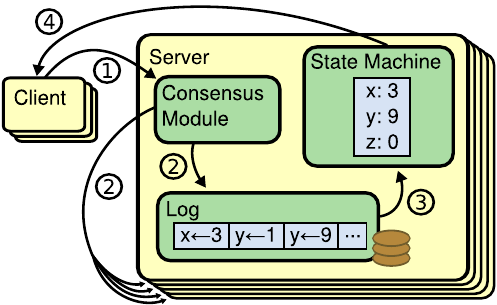
复制状态机是用于构建分布式系统的一种比较基础的架构。它的主要构成 单元包括:包含命令序列的节点日志、共识模块(例如Raft)和状态机。
复制状态机的工作原理如下:
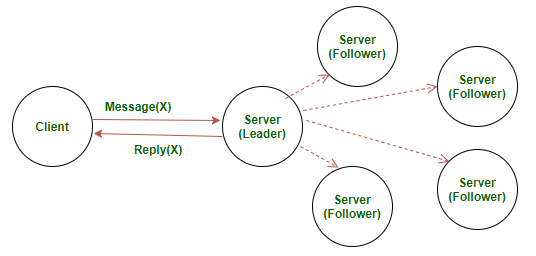
- 客户端向主导节点(Leader Node)发送包含命令的请求
- 主导节点将收到的请求追加到其日志中,并将该请求发送给所有的 跟随节点(Follower Node)。跟随节点也会将该请求追加到自身的日志中 并返回一个确认消息
- 一旦主导节点收到大部分跟随节点的确认消息,就会将命令日志 提交给其管理的状态机。一旦主导节点提交了日志,跟随节点也会 将日志提交给自身管理的状态机
- 主导节点向客户端返回响应结果
那么,Raft在复制状态机架构中扮演什么角色?
Raft的作用是确保跟随节点的日志与主导节点的日志保持一致(即:日志复制), 这样整个分布式系统的行为看起来是一致的,即使部分节点出现故障也没有影响。
另一个问题,客户端是否需要了解哪个是主导节点?
答案是NO,客户端可以向任何一个节点发送请求,如果该节点是主导节点, 那么它会直接处理请求,否则的话,该节点会转发请求给主导节点。
3、Raft共识的基本特性
3.1 Raft节点状态
对于Raft算法而言,每个节点只能处于三个状态之一:
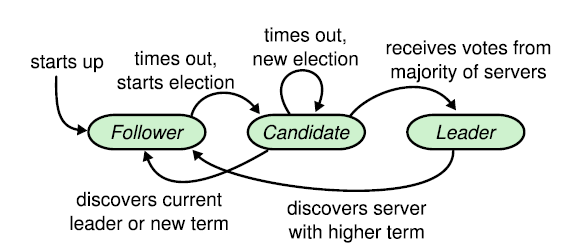
跟随状态:初始情况下,所有的节点都处于跟随状态,也就是都是跟随节点。 一旦某个跟随节点没有正常通信,它就转换为候选状态(Candidate),也就是 成为一个候选节点。跟随节点的日志可以被主导节点重写。
候选状态:处于候选状态的节点会发起选举,如果它收到集群中大多数成员的 投票认可,就转换为主导状态。
主导状态:处理客户端请求并确保所有的跟随节点具有相同的日志副本。主导 节点不可以重写其自身的日志。
如果候选节点发现已经选出了主导节点,它就会退回到跟随状态。同样,如果 主导节点发现另一个主导节点的任期(Term)值更高,它也会退回到跟随状态。
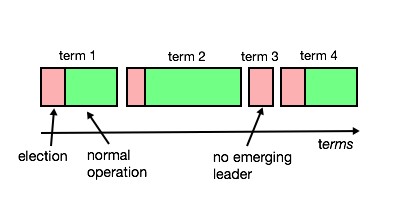
任期(Term)是一个单调递增的整数值,用来标识主导节点的管理周期。 每个任期都从选举开始,直到下一个任期之前。
3.2 Raft主导节点的选举
Raft使用心跳机制来出发主导节点的选举。当节点启动后进入跟随状态, 只要它能从主导节点或候选节点收到有效的RPC心跳消息,就会保持在跟随状态。 主导节点会周期性发送心跳消息(没有日志项的AppendEntries RPC消息)给 所有的跟随节点来维持其主导地位。如果某个跟随节点在一段时间内没有 收到心跳消息,就发生选举超时事件,该节点就认为目前没有主导节点并 发起选举来选出新的主导节点。
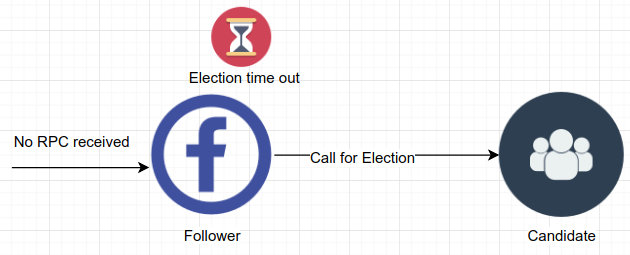
要开始一个选举,跟随节点会递增其当前任期值并转换到候选状态。该节点 首先给自己投一票,然后同时向其他节点发送请求投票的消息(RequestVote RPC消息)。

候选节点会保持在候选状态,直到以下事件发生:
- 该节点胜出选举
- 其他节点胜出选举
- 没有节点胜出选举
如果该节点收到大部分节点的投票认可,就可以胜出选举,那么该节点 就转换到主导状态成为新的主导节点。注意:每个节点只能投一票。
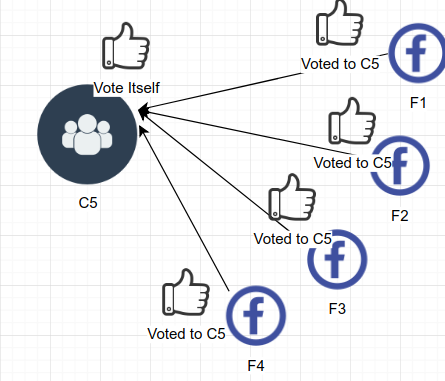
如果同时也有其他节点宣布自己是主导节点并有更高的任期值,那么任期值高的节点 成为新的主导节点:
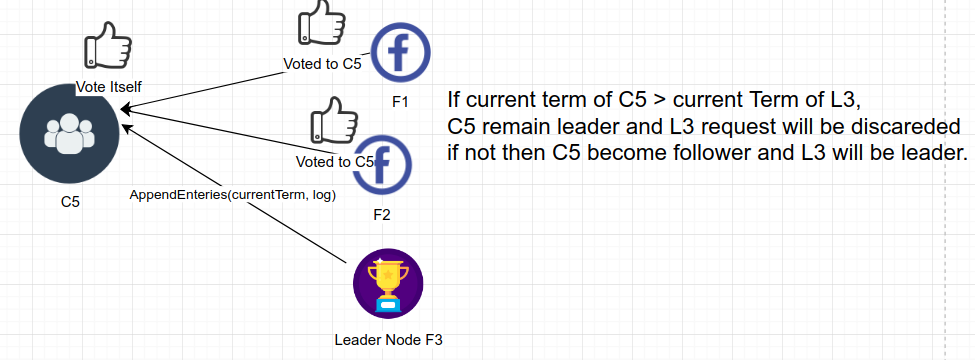
如果多个候选节点的得票情况相同,那么没有胜出节点。
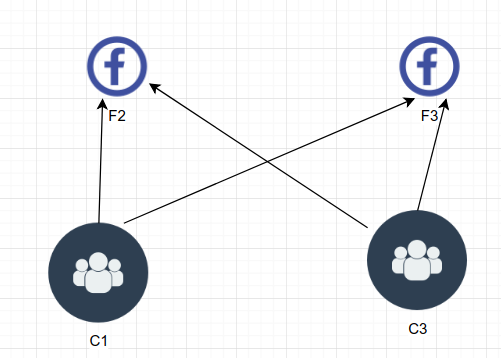
要避免出现这种情况,可以重新初始化选举并确保每个节点的选举超时 时长是随机的,以避免跟随节点同时进入候选状态。
3.3 日志复制
一旦选出主导节点,它就开始处理客户端的请求。请求中包含有复制状态机 需要执行的命令。主导节点将命令追加到自己的日志中,然后并行发送AppendEntries RPC消息给所有跟随节点复制这个新的日志项。当新的日志项被安全复制后, 主导节点会在自身的状态机上执行这个日志项里的命令,并将结果返回给 客户端。
如果跟随节点崩溃、运行缓慢或网络发生丢包问题,主导节点会无限重试 发送AppendEntries RPC消息(即使它已经向客户端返回了响应结果),知道 所有的跟随节点最终得到一致的日志副本。

当发送AppendEntries RPC消息时,主导节点会同时发送新日志项的前序 日志项的序号和任期值。如果跟随节点在自身日志中没有发现相同的序号 和任期值,就会拒绝新的日志项。因此如果AppendEntries成功返回,主导 节点就知道跟随节点的日志与自己是完全一致的。

当出现不一致情况时,主导节点强制跟随节点复制自己的日志。
4、Hyperledger Fabric的Raft排序服务实现
基于Raft的排序服务替代了之前的Kafka排序服务。每个排序节点都有其自己的Raft 复制状态机来提交日志。客户端利用Broadcast RPC发送交易提议。Raft排序节点 基于共识生成新的区块,当对等节点发送Deliver RPC时,将区块发送给对等节点。
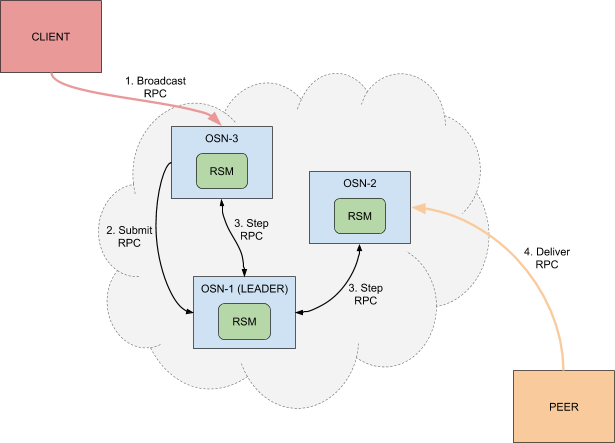
Raft排序节点的工作流程如下:
- 交易(例如提议、配置更新)应当自动路由到通道的当前主导节点
- 主导节点检查交易验证的配置序列号是否与当前配置序列号一致,如果不一致的 话则执行验证,并在验证失败后驳回交易。通过验证后,主导节点将收到的交易 传入区块切割模块的Ordered方法,创建候选区块
- 如果产生了新的区块,主导排序节点将其应用于本地的Raft有限状态机(FSM)
- 有限状态机将尝试复制到足够数量的排序节点,以便提交区块
- 区块被写入接收节点的本地账本
每个通道都会运行Raft协议的单独实例。换句话说,有N个通道的网络,就有 N个Raft集群,每个Raft集群都有自己的主导排序节点。
5、基于Raft共识的Hyperledger Fabric网络实战
我们使用BYFN组件展示raft共识模块的使用方法。BYFN包含5个排序节点, 2个组织4个对等节点,以及可选的CouchDB。在configtx.yaml文件中给出了 Raft排序服务的配置。
用下面的脚本命令启动默认的go链码和raft共识,该脚本会自动生成必要的 密码学数据:
1 | cd fabric-samples/first-network |
查看排序服务:
1 | docker logs -f ordrer3.example.com |
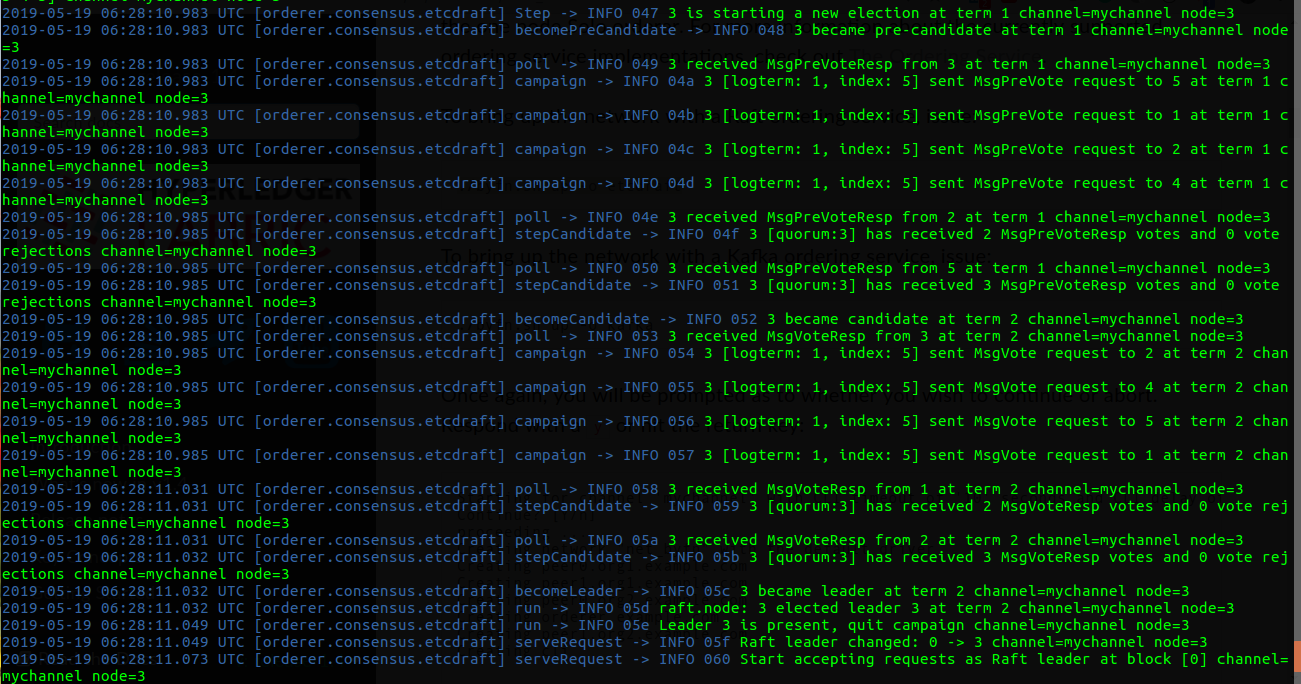
现在我们验证Raft的容错能力。
首先停掉Node3:
1 | docker stop orderer3.example.com |

然后停掉Node5:
1 | docker stop orderer5.example.com |
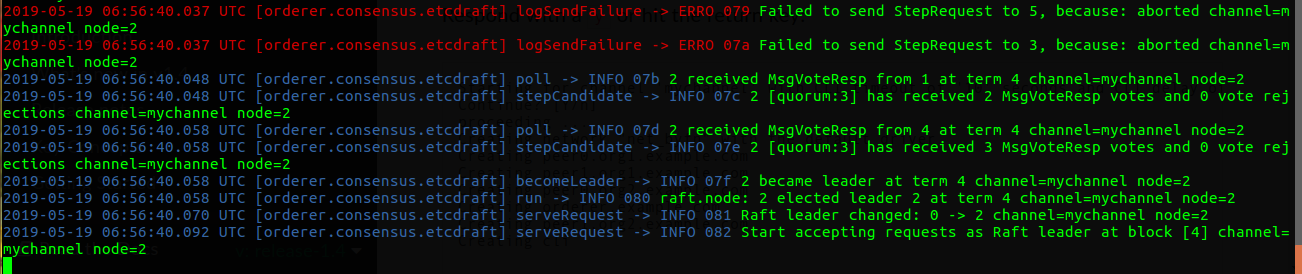
现在验证系统的有效性,可以看到系统依然可以正常响应客户端的请求:


原文链接:Detail Analysis of Raft & its implementation in Hyperledger Fabric
汇智网翻译整理,转载请标明出处