Streamlit是一个出色的机器学习工具开发库,这个教程将学习 如何使用streamlit和flair开发一个twitter微博情感分析的应用。
相关链接:Streamlit开发手册
1、streamlit概述
并不是每个人都是数据科学家,但是每个人都需要数据科学带来的力量。 Streamlit帮我们解决了这个问题,利用streamlit部署机器学习模型简单 到只需要几个函数调用。
例如,如果运行下面的代码:
1 | import streamlit as st |
Streamlit就会创建出像下面这样的滑杆输入:
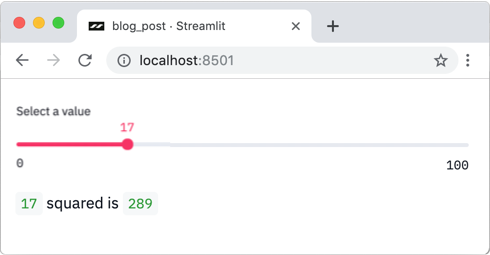
安装Streamlit也很简单:
1 | pip3 install streamlit |
然后你就可以运行应用了:
1 | streamlit run <FILE> |
注意,直接用python运行你的streamlit文件是不行的!
本文中的代码可以到这里下载。
2、情感分类
情感分类是自然语言处理(NLP)中的一个经典问题,目的是判断一个语句 的情感倾向是积极(Positive)还是消极(Negative)。
例如,“I love Python!”这句话应当被归类为Positive,而“Python is the worst!” 则应当被归类为Negative。
3、Flair开发库
很多流行的机器学习开发库都提供了情感分类器的实现,从简单和效果 方面考虑,在这个教程里我们使用Flair,一个顶级的NLP分类器开发包。
可以执行如下命令安装Flair:
1 | pip3 install flair |
4、Sentiment140数据集
任何数据科学项目都需要数据集,Sentiment140数据集是我们这个项目的绝配。 该数据集包含了160万条标注好的tweet微博,标注0表示消极,4表示积极。
可以从这里下载Sentiment140数据集。
5、数据载入及预处理
一旦下载好Sentiment140数据集,就可以使用如下代码载入数据:
1 | import pandas as pd |
运行上面的代码将输出如下结果:
1 | sentiment text |
不过,因为我们使用.sample(frac=1)随机打乱了数据的先后次序,
你得到的结果可能略有不同。
现在数据还很乱,我们先进行预处理:
1 | import re |
上面的函数略为有点乏味,但是简而言之,这段代码的目的是剔除文本中所有不能识别的字符、 链接等并截断为280个字符。有更好的办法来进行链接清理等预处理,不过我们这里就用最 朴素的方法了。
Flair对数据格式有特定的要求,看起来是这样:
1 | __label__<LABEL> <TEXT> |
在我们的微博情感分析应用中,数据整理后应该是这样:
1 | __label__4 <PRE-PROCESSED TWEET> |
为此,我们需要三个步骤:
1、执行预处理函数
1 | tweet_data['text'] = tweet_data['text'].apply(preprocess) |
2、在每个情感标记前添加__label__前缀
1 | tweet_data['sentiment'] = '__label__' + tweet_data['sentiment'].astype(str) |
3、保存数据
1 | import os |
在上面的代码中,你可能注意到了两个问题:
- 我们仅保存了部分数据。这是因为Sentiment140数据集太大了,如果Flair加载 完整的数据集需要太多的内存。
- 我们将数据分割为训练集、测试集和开发集。当Flair载入数据时,它需要数据 按这种方法拆分。默认情况下,拆分比例为8-1-1,即80%的数据进训练集、10% 的数据进测试集、10%的数据进开发集
现在,数据准备好了!
6、基于Flair的文本情感分类实现
在这个教程中,我们仅涉及Flair的基础。如果你需要更多细节,推荐你查看 Flair的官方文档。
首先我们用Flair的NLPTaskDataFetcher 类载入数据:
1 | from flair.data_fetcher import NLPTaskDataFetcher |
然后我们构造一个标签字典来记录语料库中分配给文本的所有标签:
1 | label_dict = corpus.make_label_dictionary() |
现在可以载入Flair内置的GloVe词嵌入了:
1 | from flair.embeddings import WordEmbeddings, FlairEmbeddings |
注释掉的两行代码是Flair提供的选项,用于得到更好的效果,不过我的内存有限, 因此无法进行测试。
载入词嵌入向量后,用下面的代码进行初始化:
1 | from flair.embeddings import DocumentRNNEmbeddings |
现在整合词嵌入向量和标签字典,得到一个TextClassifier模型:
1 | from flair.models import TextClassifier |
接下来我们可以创建一个ModelTrainer实例来用我们的语料库训练模型:
1 | from flair.trainers import ModelTrainer |
一旦开始训练,我们需要等一会儿了:
1 | trainer.train('model-saves', |
在模型训练完之后,可以使用如下的代码进行测试:
1 | from flair.data import Sentence |
你应该可以得到类似下面这样的结果:
1 | [4 (0.9758405089378357)] [0 (0.8753706812858582)] |
看起来预测是正确的!
7、抓取twitter微博
不错,现在我们有了一个可以预测单条tweet的感情色彩是积极或消极。 不过这还不是太有用,那么应该怎么改进?
我的想法是抓取指定查询条件的最新tweet微博,逐个进行情感分类, 然后计算积极/消极的比率。
我个人喜欢用twitterscraper来抓twitter微博,虽然它不算快,但你可以 绕过twitter设置的请求限制。用下面的命令安装twitterscraper:
1 | pip3 install twitterscraper |
安装好了。稍后我们再进行具体的抓取。
8、编写Streamlit脚本
创建一个新的文件main.py,然后先引入一些模块:
1 | import datetime as dt |
接下来,我们可以进行一些基本的处理,例如设置页面标题、载入分类模型:
1 | # Set page title |
with st.spinner这部分代码块让我们可以在加载分类模型时
给用户一个进度提示。
接下来我们可以复制之前写的预处理函数:
1 | import re |
我们首先实现单个tweet微博的分类:
1 | st.subheader('Single tweet classification') |
只要输入文本不是空的,我们就进行如下处理:
- 预处理tweet微博
- 进行预测
- 显式预测结果
1 | if tweet_input != '': |
使用st.write可以写入任何文本, 甚至可以直接显式Pandas数据帧。
好了,现在可以运行:
1 | streamlit run main.py |
结果看起来是这样:
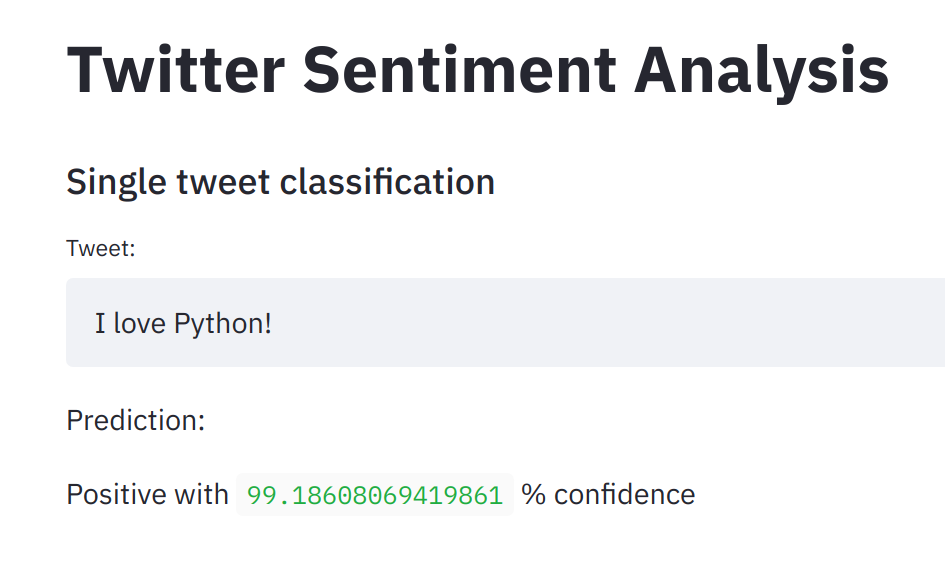
接下来我们可以实现之前的想法了:搜索某个主题的twitter微博并 计算情感正负比。
1 | st.subheader('Search Twitter for Query') |
最后,我们显示采集的数据:
1 | try: |
再次运行应用,结果如下:

下面我们完整的streamlit应用脚本:
1 | import datetime as dt |
原文链接:Building a Twitter Sentiment-Analysis App Using Streamlit
汇智网翻译整理,转载请标明出处