虽然scikit-learn在机器学习领域很重要,但是很多人并不知道 利用这个库中的一些强大的功能。本文将介绍scikit-learn中5个 最有用的5个隐藏的瑰宝,充分利用这些秘密武器将有效提高你的 机器学习处理的效率!
1、数据集生成器
Scikit-learn有很多数据集生成器,可以用来生成各种复杂度和维度 的人工数据集。
例如,make_blobs函数可以创建包含很多数据样本、聚类中心、维度的
“blobs”或数据聚类。可视化以后可以清晰看出样本的分布:
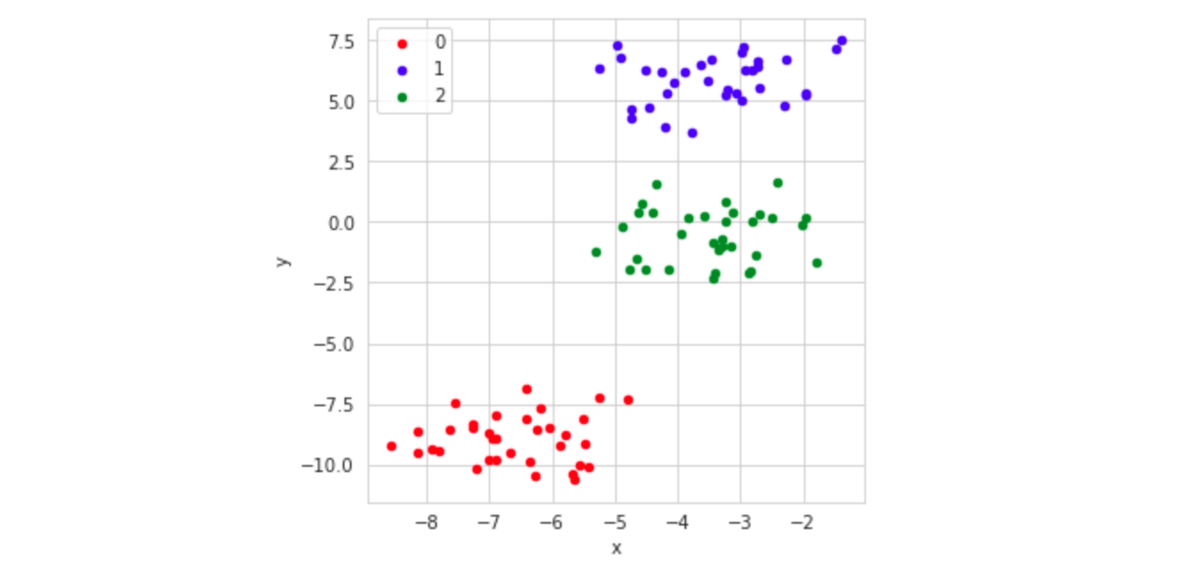
Scikit-learn其实提供了很多数据集创建函数:

- make_moons(n_samples=100, noise=0.1)
- make_circles(n_samples=100, noise=0.05)
- make_regression(n_samples=100, n_features=1, noise=15)
- make_classification(n_samples=100)
2、流水线/Pipeline
流水线可以将不同的方法组合为单一模型,在自然语言处理(NLP)应用中 这一点非常重要。可以通过组合多个模型的方式来创建流水线,数据将依次 流过聚合模型中的各环节。流水线有标准的拟合与预测能力,这使得训练 过程得到很好的组织。
很多对象都可以整合进流水线:
- 缺失值处理器/Imputers:如果你的数据中包含缺失的数据,可以试试Simple Imputer或KNN Imputer
- 编码器/Encoders:如果你的数据不是二进制分类,你可能需要使用一个Label Encoder或者One-Hot Encoder
- NLP矢量化处理器/NLP Vectorizers:如果你在处理NLP数据,那么可以使用Count Vectorizer、TD-IDF Vectorize或者Hash Vectorizer
- 数值变换:可以尝试标准化处理器、min-max缩放等等
3、网格搜索/GridSearchCV
在机器学习中的一个常见任务就是找出模型的正确参数集。通常你可以基于对 任务的理解猜测参数的取值,或者编程找出最优集合。sklearn内置了函数GridSearchCV 可以自动找出最优参数集。
GridSearchCV对象需要两个参数:首先是要训练的模型对象,例如下面示例中的SVM分类器, 第二个则是一个描述参数模型的字典,字典的每一个键对应模型的一个参数,键值则是可能 取值的列表。
1 | from sklearn import svm, datasets |
网格搜索完成后,best_params属性中就记录了表现最好的模型参数。
4、验证曲线/validation_curve
要可视化一个参数对模型性能的影响,可以使用sklearn的validation_curve。 这个函数需要一些参数 —— 模型、要调整的参数、参数的取值范围、运行的次数等。validation_curve 类似于单变量的网格搜索,可以帮助你更好的可视化单个参数变化的效果。
1 | from sklearn.model_selection import validation_curve |
validation_curve输出的结构是一个元组 —— 一个表示训练得分,另一个表示测试得分。 数组中的每个元素表示k次运行中的一个参数值。
当绘制结果后,参数和精确度之间的关系就很清晰了:
1 | import matplotlib.pyplot as plt |
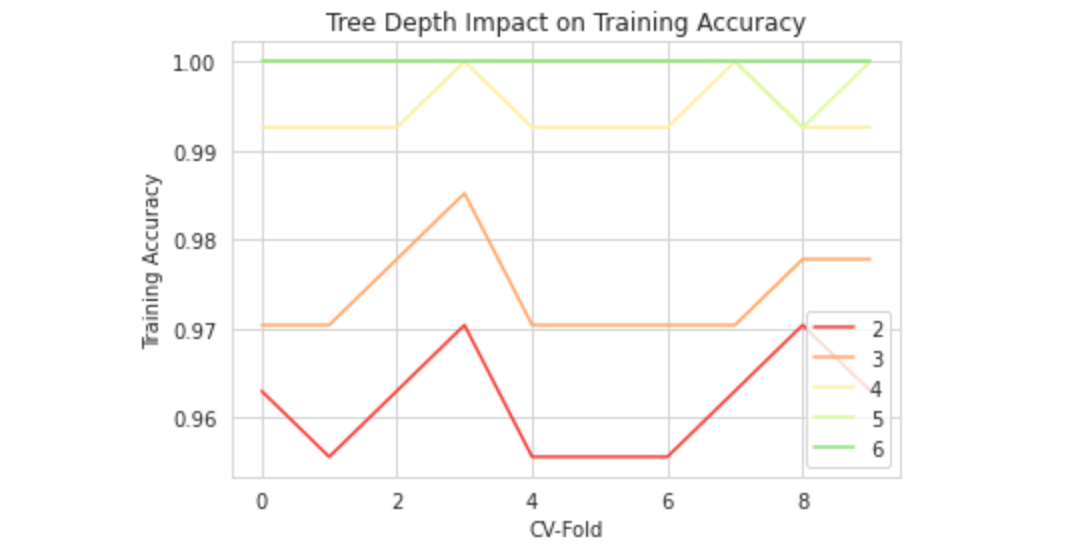
这让我们可以可视化树的深度对准确度的影响。从上图中可以 看到树深度为5或6时,模型的性能相当好,但是再继续增加深度 就会导致过拟合。
K折交叉验证
交叉验证是一种准确度高于train_test_split的方法,并且通常 需要更少的代码。在传统的训练/测试集拆分中,数据样本被随机的 分配到训练集和测试集,通常比例为7:3~8:2,在训练集上训练模型, 然后在测试集上评估模型,以确保模型真正泛化而非单纯的记忆。
然而由于每次分割是随机的,分割10次将产生10个不同的测试结果。
为了解决这个问题,K折交叉验证将数据拆分为K类,在其中K-1个 子集上训练模型,在剩下的1个子集上测试模型。重复这一过程直至 测试子集最终覆盖完整的数据集,那么就得到了完整并且可信的准确度指标。 这种方法更好的一点是,不需要跟踪x-train、x-test、y-train和y-test变量。 交叉验证唯一的缺点是需要更多时间 —— 不过要得到更好的结果总是要 多付出一点成本。
原文链接:5 Scikit-Learn Must-Know Hidden Gems
汇智网翻译整理,转载请标明出处